
Mroczne strony modularyzacji
Wprowadzenie
Trafiłem niedawno na bardzo ciekawy problem, który skłonił mnie do refleksji na temat mniej kuszących aspektów modularyzacji, o których przeważnie nie słyszymy na konferencjach czy warsztatach.
Zacznijmy może od początku, czym w ogóle jest modularyzacja? Najprościej mówiąc, jest to podział systemu na samodzielne części (moduły), z których każdy posiada:
- Jasno określoną odpowiedzialność
- Komunikuje się poprzez zdefiniowane protokoły komunikacji
- Może być rozwijany niezależnie od pozostałych modułów
W dużym skrócie jest to ukłon w kierunku zasady dziel i zwyciężaj. Zamiast zmagać się z wielkim, skomplikowanym i zagmatwanym problemem, dzielimy go na mniejsze problemy, co znacznie ułatwia ich rozwiązywanie.
Wiele osób słysząc "modularyzacja" myśli "mikroserwisy", dlatego zanim przejdziemy dalej, ustalmy jedną kwestię. Mikroserwisy to tylko jeden ze sposobów na implementację modularyzacji, tak samo jak modularny monolit.
Stan Aktualny
Wyobraźmy sobie system składający się z trzech modułów.
Uwaga: Poniższy diagram jest bardzo uproszczonym modelem, którego celem jest tylko przedstawienie problemu.
- Moduł
IAM(Identity and Access) - użytkownicy / grupy / uprawnienia - Moduł
A- zarządzanie zasobami - Moduł
B- zarządzanie innymi zasobami
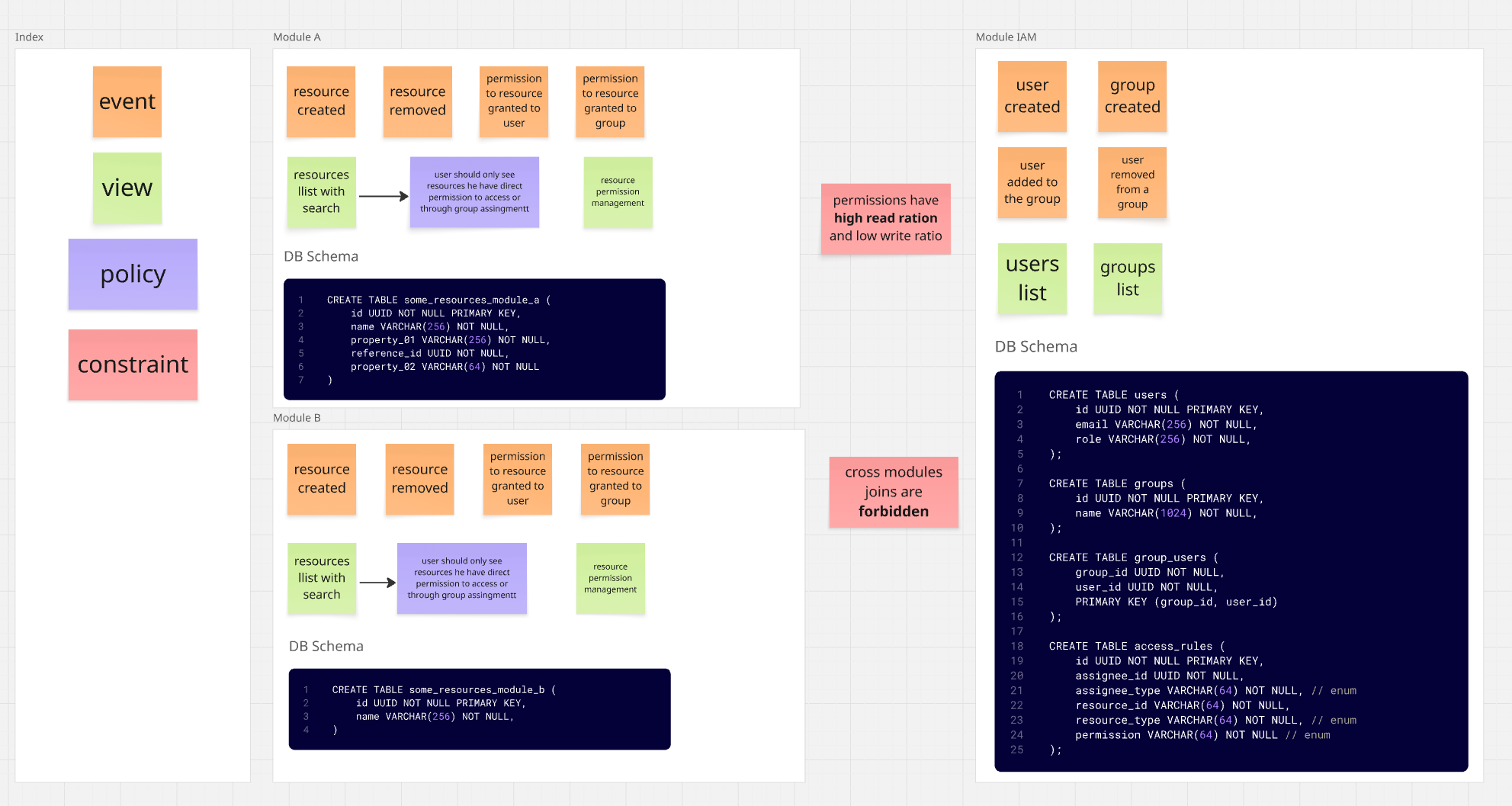
System uprawnień jest tutaj nieco skomplikowany, w głównej mierze opiera się o ACL (Access Control List),
czyli nadawanie uprawnień do zasobów bezpośrednio użytkownikom lub grupom.
Do tego występują też elementy RBAC (Role Based Access Control), gdzie użytkownicy o konkretnych
rolach mają zdefiniowane uprawnienia do konkretnych części systemu.
Mamy też częściowo ABAC (Attribute Based Access Control), gdzie uprawnienia wynikają z atrybutów użytkownika,
w tym wypadku przynależności do grupy.
Brzmi znajomo? To wcale nie jest aż tak unikalny przypadek jak mogłoby się wydawać. No ale do sedna.
Problem
System uprawnień, jak widać na diagramie, zdefiniowany jest w module IAM, czyli to tam przechowujemy
informację na temat:
- Użytkowników oraz ich ról
- Grup, do których należą użytkownicy
- Uprawnień do konkretnych zasobów
Moduły A i B natomiast są odpowiedzialne za zarządzanie swoimi zasobami, muszą jednak upewnić się, że dany użytkownik ma dostęp do konkretnego zasobu.
Schemat zależności modułów jest więc następujący: Moduły A i B wiedzą o istnieniu modułu IAM (są od niego zależne), sam moduł IAM natomiast nie ma pojęcia o istnieniu modułów A i B.
Problem, na jaki trafił zespół, to "w jaki sposób utworzyć stronicowaną listę zasobów w danym module na podstawie uprawnień użytkownika".
Lista zasobów dodatkowo ma pozwalać na:
- Filtrowanie na podstawie cech zasobu
- Sortowanie na podstawie cech zasobu
- Pozwalać zwracać tylko wybraną stronę
Powyższe wymagania znacznie utrudniają implementację, gdyby nie filtrowanie/stronicowanie, moglibyśmy uderzyć
bezpośrednio do modułu IAM z żądaniem zwrócenia zasobów dla danego użytkownika.
Cechy zasobów to wszystkie ich parametry i atrybuty, które mają sens i znaczenie głównie w obrębie swojego
kontekstu. Przykładowymi cechami zasobu mogą być jego nazwa czy data utworzenia. Są to parametry, po których
użytkownik ma mieć możliwość sortowania lub filtrowania a które nie występują w module IAM
Jednak bez cech zasobów, po których możemy filtrować/sortować, moduł IAM może co najwyżej zwrócić nam wszystkie zasoby,
a filtrowanie musielibyśmy zrobić po stronie modułu. Nie jest to jednak zbyt skalowalne rozwiązanie.
Nie wiedząc, jak wybrnąć z tej sytuacji, zespół postanowił (świadomie lub nie) złamać zasady modularyzacji i powiązać ze sobą moduły na poziomie bazy danych.
Ponieważ system wdrożony jest jako modularny monolit, a każdy moduł ma dostęp do tej samej bazy danych (każdy moduł posiada swoje tabele z odpowiednim prefixem),
teoretycznie nic nie stoi na przeszkodzie, aby budując zapytanie SQL zwracające listę zasobów dla konkretnego modułu,
podłączyć do niego tabele uprawnień z modułu IAM i odfiltrować te zasoby, do których użytkownik nie ma dostępu.
Szybkie, proste i nawet działa.
Prawdopodobnie mogłoby to tak sobie egzystować, gdyby nie jedno nowe wymaganie: musimy wydzielić jeden z modułów z monolitu...
I tutaj zaczynają się schody. Jak wydzielić moduł A jako niezależny serwis, kiedy jest on mocno sprzężony na poziomie
bazy danych z modułem IAM? Jeżeli usuniemy join do tabel IAM, kontrola dostępu przestanie
działać.
Poniżej przedstawię techniki, które pozwolą nam wydzielić ten moduł z monolitu bez utraty funkcjonalności, łamania zasad modularyzacji czy zmian w zależnościach między modułami.
Podczas projektowania modularnego monolitu, warto spróbować trochę innego podziału. Zamiast prefixować tabele, w ramach jednego serwera bazodanowego można stworzyć osobne bazy/schematy dla każdego modułu, co znacząco utrudni tworzenie przypadkowego sprzężenia na poziomie zapytań SQL.
Podział odpowiedzialności
A co gdyby to nie moduł IAM odpowiadał za uprawnienia nadawane do zasobów, które
żyją tylko w konkretnym module?
Jednym z możliwych (dla wielu pewnie najlepszym) rozwiązań jest separacja odpowiedzialności, tzn. IAM
odpowiada za autoryzację, użytkowników, ich rolę oraz grupy, do których są przypisani.
Moduły natomiast same zarządzają regułami uprawnień do zasobów. Oznacza to w praktyce przeniesienie tabel access_rules
do Module A oraz Module B.
W rezultacie otrzymalibyśmy architekturę podobną do tej poniżej:
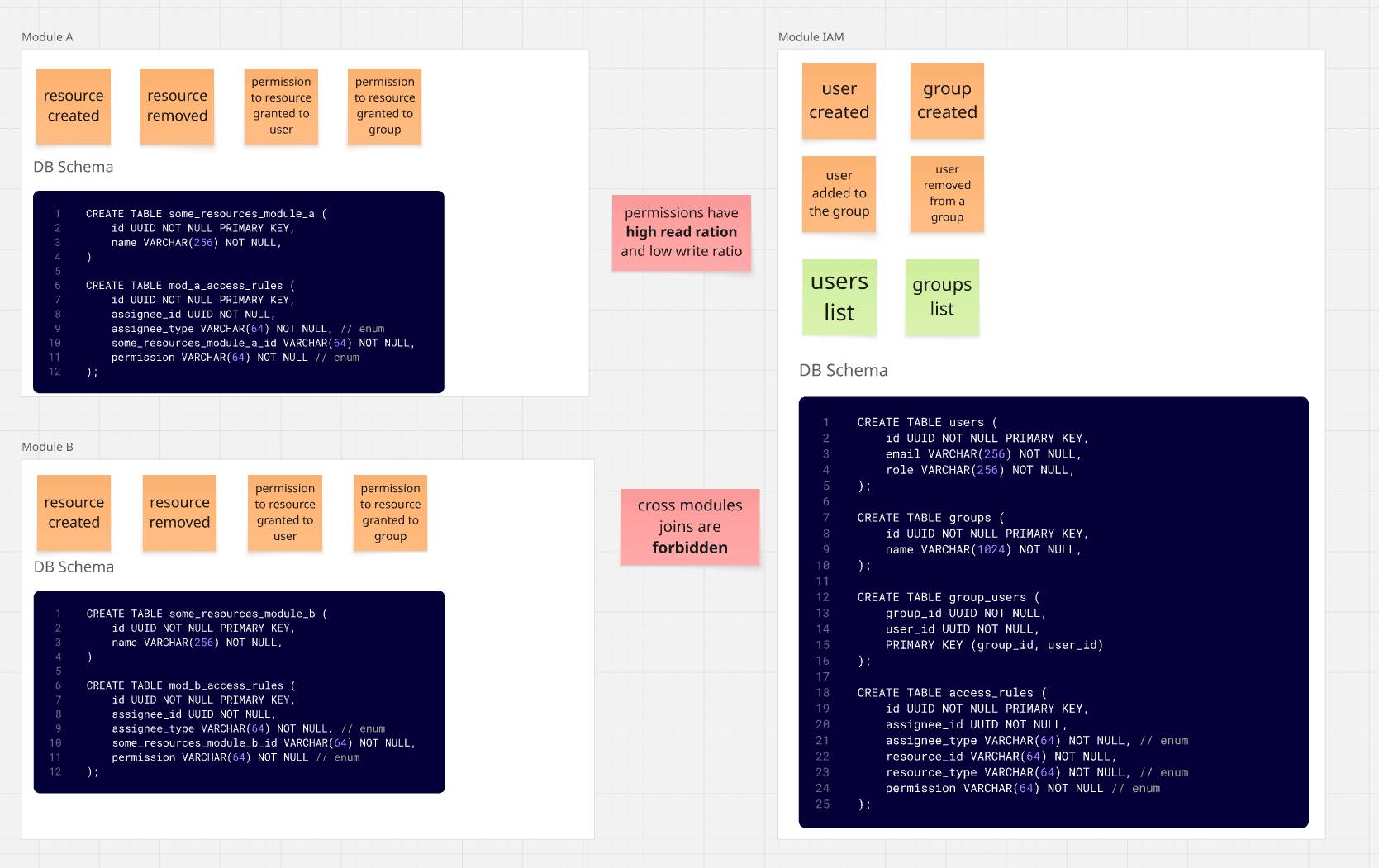
Żaden z modułów nie musi więc robić wycieczek do IAM w celu uzyskania listy zasobów dostępnych
dla wybranego użytkownika.
Mamy wprawdzie lekką duplikację – musimy dla każdego z istniejących modułów w zasadzie powtórzyć logikę uprawnień oraz wpiąć ją w istniejące mechanizmy modułów.
Uwaga: Tutaj może pojawić się pokusa stworzenia komponentu. O ile nie mamy w zespołach ludzi doświadczonych w budowaniu bibliotek / komponentów, najlepiej zacząć od duplikacji. Duplikacja w dłuższej perspektywie czasu boli o wiele mniej niż niepoprawna abstrakcja.
Tylko czy to wystarczy?
Nie do końca, jeżeli przyglądniemy się tabeli uprawnień, zauważymy, że uprawnienia mogą być nadawane bezpośrednio użytkownikowi lub grupie, do której dany użytkownik przynależy.
Oznacza to, że w Module A nadajemy uprawnienia do zasobu dla grupy Group 01, do której
należy User 01 oraz User 02.
Dzięki temu obydwaj użytkownicy mają dostęp do zasobu.
Co natomiast jeżeli usuniemy użytkownika z wybranej grupy?
Możemy do tego podejść na dwa sposoby:
- Podczas każdej weryfikacji dostępu odpytujemy moduł
IAMo listę grup użytkownika - Godzimy się na
eventual consistencyi grupy użytkownika trzymamy w sesji, którą odświeżamy co kilka/kilkanaście minut
Pierwsze rozwiązanie jest najprostsze w implementacji, nie narusza granic odpowiedzialności modułów, może jednak dość szybko stać się wąskim gardłem.
Oczywiście nie stanie się to od razu, dodatkowo ze względu na charakter danych (częstszy odczyt niż zapis) możemy też odciążyć bazę danych poprzez wprowadzenie odpowiednich mechanizmów cachujących.
W przypadku rozwiązania numer dwa musimy upewnić się, że jest to w ogóle akceptowalne rozwiązanie z punktu widzenia biznesu.
Projekcja
Innym podejściem do rozwiązania problemu jest zachowanie struktury uprawnień w module IAM, ale
wprowadzenie mechanizmów pozwalających modułom Module A oraz Module B na synchronizację
tabeli uprawnień do lokalnej projekcji.
Projekcja ta to nic innego jak uproszczona forma tabeli access_rules powielona w konkretnym module.
W rezultacie dalej otrzymujemy pewną duplikację, ale moduły Module A oraz Module B
nie skupiają się na zarządzaniu uprawnieniami – ta odpowiedzialność nadal jest oddelegowana do modułu IAM.
Ich odpowiedzialność zredukowana została do synchronizacji uprawnień z modułem uprawnień.
Tylko, jak i kiedy przeprowadzać tę synchronizację? Za każdym razem, kiedy nadajemy uprawnienia do zasobu.
Module A podczas nadawania uprawnień użytkownikowi lub grupie, do jakiegoś zasobu, najpierw
komunikuje się z modułem IAM.
To samo robimy podczas usuwania dostępu do zasobu. Najpierw usuwamy wpis w module IAM a następnie
usuwamy wpis w lokalnej projekcji.
Co natomiast jeżeli usuniemy użytkownika z wybranej grupy?
Wracamy tutaj w zasadzie do tego samego problemu, który mieliśmy w poprzednim podejściu. Możemy albo
każdorazowo pobierać listę grup użytkownika z modułu IAM, lub pogodzić się z eventual consistency.
Różnica pomiędzy separacją a projekcją jest bardzo niewielka. Z projekcjami możemy jednak pójść krok dalej.
Zdarzenia
Moduł IAM może również propagować zdarzenia dotyczące:
- Dodania użytkownika do grup
- Usunięcia użytkownika z grupy
- Usunięcia grupy
Aby zachować odpowiednią strukturę zależności, zdarzenia te nie mogą być publikowane "pod konkretnego odbiorcę".
Musimy tutaj zastosować podejście Pub/Sub, polegające na tym, że IAM wystawia zdarzenia na konkretny
Topic, do którego zainteresowane moduły mogą się zasubskrybować.
Dzięki temu obydwa moduły dostaną kopię tego samego zdarzenia, które będą mogły obsłużyć niezależnie.
Budując projekcję możemy też znacznie uprościć jej strukturę, poprzez rozbicie grup na listy użytkowników.
Jeżeli grupa otrzymuje uprawnienie typu access do jakiegoś zasobu, to zamiast przechowywać
jeden wpis w projekcji reprezentujący grupę, możemy stworzyć wpis dla każdego użytkownika grupy.
Dzięki temu podczas weryfikacji praw dostępu w ogóle nie musimy pytać moduł IAM o nic. "Wystarczy", że
zareagujemy odpowiednio na zdarzenia propagowane przez moduł IAM:
- Dodanie użytkownika do grupy
- Usunięcie użytkownika z grupy
- Usunięcie grupy
W zasadzie tylko te zdarzenia są dla nas istotne. Dodanie grupy czy użytkownika nie wpływa w zasadzie na nic, dlatego możemy śmiało je ignorować/odfiltrować.
Wiarygodność zdarzeń
Oczywiście podejście oparte o zdarzenia niesie ze sobą pewne ryzyko. Jednym z nich jest np. zaburzona kolejność
zdarzeń.
Przykładowo najpierw dostajemy zdarzenie "usunięcia użytkownika z grupy", a dopiero później "dodania", kiedy
w rzeczywistości zdarzenia te nastąpiły w odwrotnej kolejności.
Tak, to może być pewnym problemem, szczególnie kiedy w treści wiadomości zawierającej zdarzenie znajdują się też wszystkie szczegóły danego zdarzenia.
Możemy jednak temu zaradzić, decydując się na wykorzystanie zdarzeń anemicznych, czyli takich, które w zasadzie zawierają jedynie identyfikatory zasobów, których dotyczą, a po całą resztę trzeba już udać się do modułu źródłowego.
Porównajmy oba podejścia na przykładzie zdarzenia UserRemovedFromGroup:
Zdarzenie bogate (Rich Event)
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"userName": "jan.kowalski",
"userEmail": "[email protected]",
"groupId": 456,
"groupName": "Administrators",
"groupPermissions": ["read", "write", "delete"],
"removedBy": {
"userId": 789,
"userName": "admin"
}
}
}
Zdarzenie anemiczne (Anemic Event)
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"groupId": 456
}
}
Różnica jest zasadnicza. W przypadku zdarzenia bogatego cała informacja o użytkowniku, grupie i uprawnieniach jest zawarta w zdarzeniu. Jeżeli kolejność zdarzeń zostanie zaburzona, nasza projekcja może się znaleźć w niespójnym stanie.
Zdarzenie anemiczne natomiast zawiera tylko identyfikatory. Konsument po otrzymaniu takiego zdarzenia musi
wykonać dodatkowe zapytanie do modułu IAM, aby pobrać aktualny stan. Dzięki temu niezależnie od kolejności
otrzymania zdarzeń zawsze otrzymamy najbardziej aktualną wersję danych.
Scenariusz problematyczny dla Rich Events
Wyobraźmy sobie następującą sekwencję zdarzeń w module IAM:
10:00:00- Użytkownik dodany do grupy "Administrators"10:00:05- Użytkownik usunięty z grupy "Administrators"
Konsument w Module A otrzymuje zdarzenia w odwrotnej kolejności:
- Otrzymuje
UserRemovedFromGroup(z danymi z 10:00:05) - Otrzymuje
UserAddedToGroup(z danymi z 10:00:00)
W przypadku rich events, projekcja w Module A pokazuje, że użytkownik należy do grupy (bo ostatnie otrzymane zdarzenie to "dodanie"), mimo że w rzeczywistości został już z niej usunięty.
W przypadku anemic events, niezależnie od kolejności otrzymania, Module A wykona zapytanie do IAM i otrzyma aktualny stan - użytkownik nie należy do grupy.
Zdarzenia anemiczne redukują ryzyko niespójności, ale nie eliminują go całkowicie. Nadal możliwa jest sytuacja, gdzie między otrzymaniem eventu a zapytaniem do IAM stan się zmieni. Można więc rozważyć dodanie version number lub timestamp do eventów i sprawdzać je przy aktualizacji projekcji. Chociaż mechanizmy zabezpieczające będą w dużej mierze wynikać z ruchu i częstotliwości zmian.
Przedstawia się to w następujący sposób:
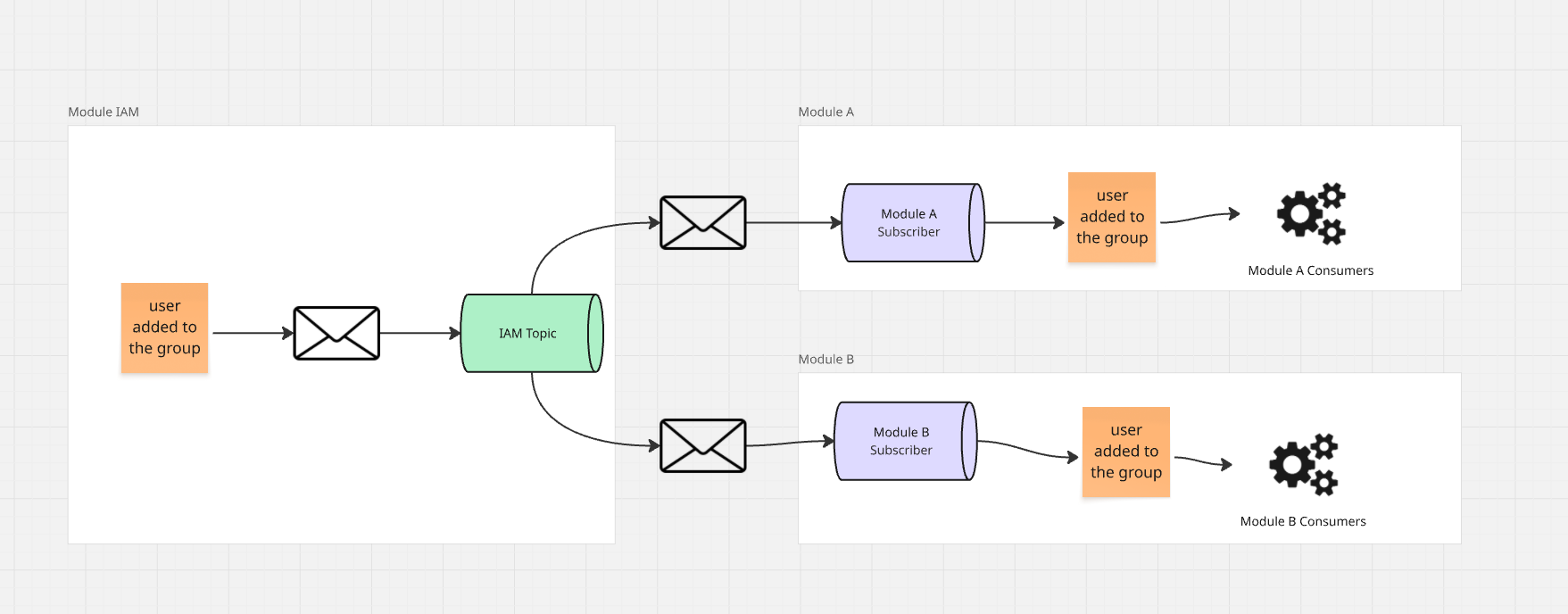
Kiedy konsument modułu A otrzymuje informację, jego rolą jest udać się do modułu IAM i zapytać go
o wszystkie reguły dla konkretnej grupy. Moduł IAM może zwrócić nam rekordy z tabeli uprawnień dotyczących
konkretnej grupy, a następnie, jeżeli jakiekolwiek reguły występują, możemy zapytać o użytkowników tej grupy i w
lokalnej projekcji modułu zbudować dla nich projekcję uprawnień.
Możemy też delikatnie ułatwić sobie życie i do protokołu komunikacji z modułem IAM dołożyć możliwość
pobierania płaskiej struktury uprawnień, która zwróci nam nie grupę, a listę użytkowników grupy z uprawnieniami do
konkretnego zasobu.
Uwaga: W celu zapewnienia dodatkowej gwarancji dostarczenia zdarzeń, warto rozważyć implementację wzorca Outbox.
Chwila, ale czy znowu moduł IAM nie stanie się wąskim gardłem?
Nie do końca, istotna jest tutaj nie tylko samo zapytanie, ale raczej jego częstotliwość. Kontrola uprawnień to jeden z tych procesów, gdzie znacznie częściej pytamy o uprawnienia, niż je zmieniamy.
Oczywiście nie należy wierzyć mi na słowo, posiadając istniejący system z kontrolą uprawnień, warto to po prostu zmierzyć.
Wracając jednak do sedna, w przypadku wykorzystania zdarzeń anemicznych nie musimy aż tak bardzo przejmować się kolejnością ich otrzymywania. Nie opieramy się bowiem na treści zdarzenia, a jedynie na identyfikatorze zasobu, którego dotyczy, co znacznie ułatwia budowanie projekcji.
Ma to jednak swój koszt, koszt polegający na tym, że teraz po każdym zdarzeniu musimy udać się do źródła w celu ustalenia stanu faktycznego.
Warto więc przeanalizować to podejście pod kątem wydajności.
Technik radzenia sobie ze zdarzeniami jest jednak więcej, jedną z nich znajdziecie na https://event-driven.io/.
Duplikacja
W obydwu podejściach pojawia się jednak problem duplikacji. Chociaż w tym wypadku "problem" to chyba złe słowo. Jest to po prostu koszt modularyzacji, o którym się po prostu nie mówi.
Niezależnie czy zdecydujemy się na separację odpowiedzialności, czy budowanie projekcji, moduły A oraz B będą mniej lub bardziej powielać logikę związaną z uprawnieniami.
Dlatego niezależnie od naszego modelu wdrożeniowego (monolit / mikroserwisy) oraz niezależnie od tego, jak wydzielimy granice modułów oraz ich odpowiedzialności, musimy po prostu przygotować się na ten koszt.
Moja rada jest tutaj zawsze taka, aby zacząć od duplikacji. Nawet jeżeli nasze implementacje nie różnią się absolutnie niczym pomiędzy modułami.
O wiele łatwiej jest wyciągać części wspólne z istniejących rozwiązań, niż projektować części wspólne dla rozwiązań jeszcze nieistniejących.
Co będzie lepsze?
Na to pytanie nie ma jednoznacznej odpowiedzi. Możemy jednak spróbować przeanalizować naszą sytuację i wybrać takie rozwiązanie, które pozwoli nam wydzielić jeden z modułów oraz pozbyć się sprzężenia na poziomie bazy danych.
Dla modułu, który ma zostać wydzielony, sugerowałbym (o ile jest to możliwe) separację odpowiedzialności oraz przeniesienie zarządzania uprawnieniami do zasobów do tego modułu.
Skoro i tak musimy wykonać pewną pracę, skoro i tak musimy ten moduł odseparować fizycznie od naszego monolitu,
możemy też pójść krok dalej i stosunkowo niewielkim kosztem zredukować jeszcze bardziej jego zależność od
IAM.
Czy jednak taka operacja ma sens dla istniejących modułów?
Dla modułów, które nie muszą być wydzielane i dalej będą żyły w ramach modularnego monolitu, sugerowałbym podejście oparte o projekcję, jednak niekoniecznie o zdarzenia.
Projekcje bez zdarzeń
Jest to technika, która nie sprawdzi się w podejściu mikroserwisowym, ale może pomóc doraźnie. Nie tylko pomóc, ale też nakreślić kierunek na przyszłość. Można ją zaimplementować niskim kosztem, otrzymując w zasadzie to samo co przy podejściu opartym o zdarzenia.
Popatrzmy na to z innej perspektywy. Pub/Sub to w zasadzie mechanizm pozwalający nam na pewną formę replikacji. Dzięki zdarzeniom, posiadamy wiedzę, że coś miało miejsce w jakimś momencie w jakimś module.
A co gdyby zamiast publikować zdarzenie na Topic wykorzystać Materialized Views?
Tak, wielu osobom zapewne w tym momencie zapala się czerwona lampka. No bo jak to tak, materialized view? Logika po stronie bazy danych zamiast w kodzie?
Cóż, nie jest to rozwiązanie idealne. Wprawdzie pozbywamy się sprzężenia na poziomie SQL, ale w zamian otrzymujemy inne sprzężenie, tym razem na poziomie bazy danych.
Jeżeli jednak podejdziemy do tego pragmatycznie, to finalnie wymieniamy po prostu mechanizm transportu. Zamiast budować pub/sub, implementować Outbox pattern, obsługiwać błędy komunikacji sieciowej, retry itp. możemy po prostu pozwolić bazie danych na replikację danych.
Jeżeli z jakiegokolwiek powodu przestanie nam się to sprawdzać, np. kiedy odświeżanie zmaterializowanego widoku będzie zbyt kosztowne i niepotrzebnie zacznie obciążać naszą bazę danych, nic nie będzie stało na przeszkodzie, aby przerzucić się na projekcje.
Zanim jednak do tego dojdziemy, możemy też spróbować sam proces odświeżania wrzucić na kolejkę w module IAM
i realizować go asynchronicznie. Dostaniemy lekkie opóźnienie, chociaż w tym wypadku powinno być ono na akceptowalnym poziomie.
Kluczowe jest zrozumienie, że Materialized View nie jest rozwiązaniem ani złym, ani dobrym – daje nam jednak
możliwość stosunkowo szybkiego wprowadzenia uproszczonej separacji bez konieczności budowania całego mechanizmu opartego o zdarzenia.
Kiedy jednak pełna separacja/wydajność/vendor locking lub cokolwiek innego zacznie nam tutaj doskwierać, nie powinno być większych problemów z przejściem na projekcje.
Właśnie to czyni Materialized View interesującym rozwiązaniem.
Rozwiązanie idealne
Nie istnieje...
I to chyba najważniejsze co chciałbym przekazać w tym artykule.
Nawet jeżeli uda się nam zredukować problem tylko i wyłącznie do technologii i nawet jeżeli jakimś cudem
wszyscy zgodzilibyśmy się, że problem A należy rozwiązać wzorcem/techniką/architekturą B.
Nic z tego może nie mieć znaczenia, biznes najzwyczajniej w świecie może nie wyrazić zgody na większy refactoring...
I nie musi to być zła wola lub ignorancja, czasami po prostu nie mamy zasobów.
Ciężko jest uzasadnić, dlaczego mielibyśmy poświęcić czas na to, aby zarządzanie uprawnieniami przenieść do modułów, kiedy wszystko działa i generuje zyski.
Tak samo ciężko będzie uargumentować, dlaczego nagle, mając wymaganie wydzielenia jednego modułu, musimy poprawić wszystkie pozostałe, dodając do nich komunikację asynchroniczną, zdarzenia, mechanizmy retry, recovery itp.
Warto pogodzić się z faktem, że świat nie jest idealny, nie jest czarno-biały i często będziemy musieli wybierać pomiędzy kilkoma niedoskonałymi rozwiązaniami.
To, co w jednym miejscu może wydawać się absolutnie niepoprawne, w innym kontekście może być już akceptowalne, albo wręcz pożądane.
Pomoc
A gdybyś zmagał się podobnymi problemami w swoim projekcie i nie bardzo wiedział, jak je rozwiązać.
Skontaktuj się ze mną, a wspólnie znajdziemy rozwiązanie, które będzie idealnie dopasowane do Twoich potrzeb.
Zachęcam również do odwiedzenia serwera Discord - Flow PHP, na którym możemy porozmawiać bezpośrednio.
