
The Dark Sides of Modularization
Introduction
I recently ran into a pretty interesting problem that got me thinking about the less glamorous aspects of modularization - you know, the stuff we don't usually hear about at conferences or workshops.
Let's start with the basics. What exactly is modularization? Simply put, it's breaking down a system into independent parts (modules), where each one has:
- A clearly defined responsibility
- Communication through defined protocols
- The ability to be developed independently from other modules
In a nutshell, it's a nod toward the divide and conquer principle. Instead of wrestling with one massive, complicated, tangled problem, we break it into smaller problems that are much easier to solve.
A lot of people hear "modularization" and immediately think "microservices." So before we go any further, let's clear one thing up. Microservices are just one way to implement modularization, same as a modular monolith.
The Current State
Picture a system made up of three modules.
Note: The diagram below is a very simplified model - its only purpose is to illustrate the problem.
IAMModule (Identity and Access) - users / groups / permissionsModule A- resource managementModule B- different resource management
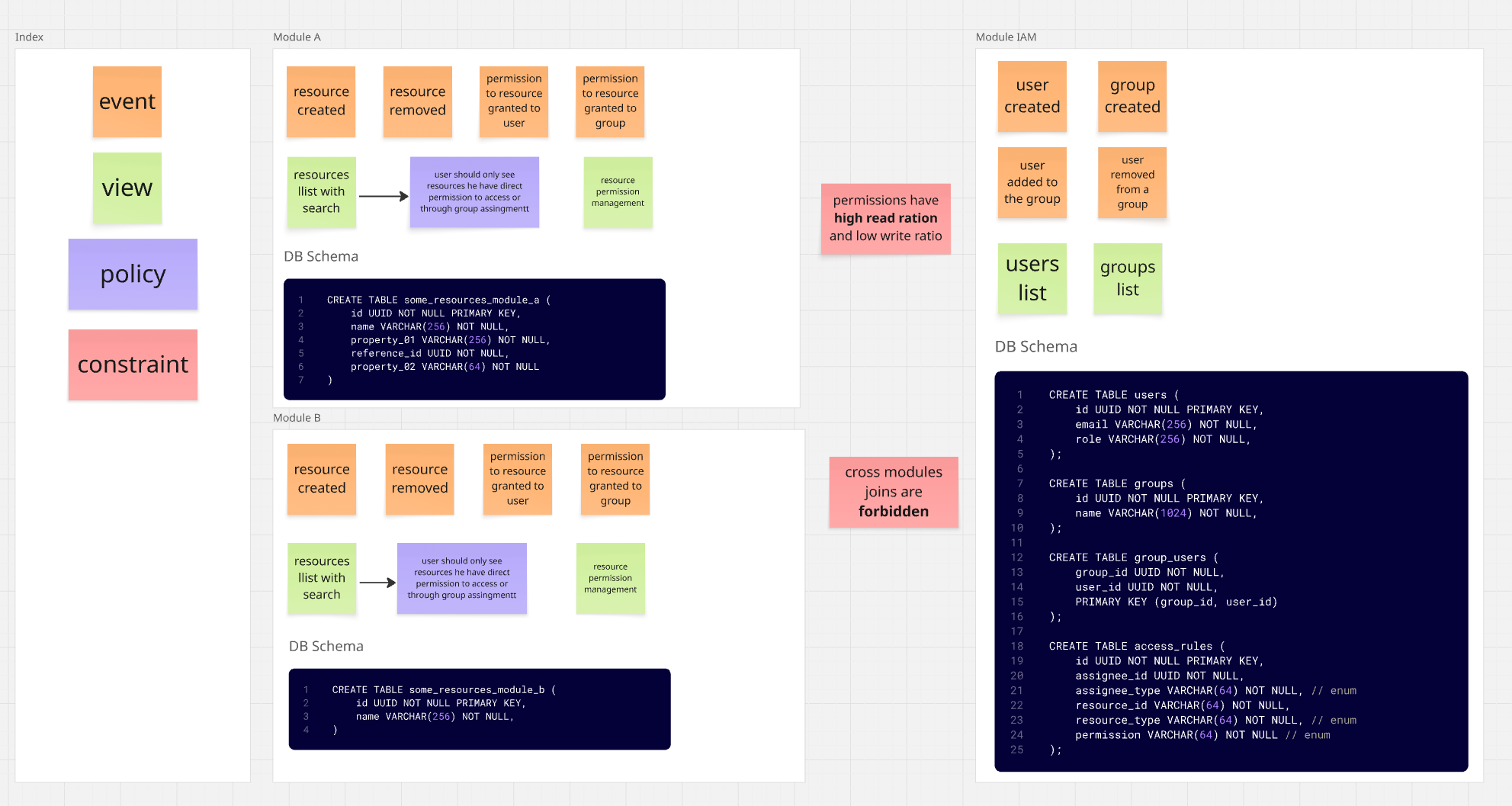
The permissions system here is a bit complex. It's mainly based on ACL (Access Control List),
which means granting permissions to resources directly to users or groups.
On top of that, there's also some RBAC (Role Based Access Control), where users with specific
roles have defined permissions to specific parts of the system.
We also have partial ABAC (Attribute Based Access Control), where permissions are derived from user attributes,
in this case, group membership.
Sound familiar? This isn't as unique a case as you might think. But anyway, let's get to the point.
The Problem
As you can see in the diagram, the permission system is defined in the IAM module - that's where we store
information about:
- Users and their roles
- Groups that users belong to
- Permissions for specific resources
Modules A and B, meanwhile, are responsible for managing their own resources but need to verify that a given user has access to a specific resource.
So the module dependency scheme looks like this: Modules A and B know about the existence of the IAM module (they're dependent on it), but the IAM module itself has no clue that Modules A and B exist.
The problem the team ran into was this: "How do we create a paginated list of resources in a given module based on user permissions?"
Additionally, the resource list needs to allow:
- Filtering based on resource characteristics
- Sorting based on resource characteristics
- Returning only a selected page
These requirements make implementation significantly harder. If we didn't have filtering/pagination, we could just
hit the IAM module directly with a request to return resources for a given user.
Resource characteristics are all their parameters and attributes that make sense and have meaning mainly within their
own context. Example resource characteristics might be its name or creation date. These are parameters that
the user should be able to sort or filter by, but they don't exist in the IAM module.
But without resource characteristics that we can filter/sort by, the IAM module can at best return all resources,
and we'd have to do the filtering on the module side. Not exactly a scalable solution.
Not knowing how to get out of this situation, the team decided (consciously or not) to break the rules of modularization and couple the modules at the database level.
Since the system is deployed as a modular monolith and each module has access to the same database (each module has its own tables with an appropriate prefix),
theoretically nothing stands in the way of building an SQL query that returns a list of resources for a specific module
and joining it with permission tables from the IAM module to filter out resources the user doesn't have access to.
Quick, simple, and it even works.
This could probably coexist peacefully, except for one new requirement: we need to extract one of the modules from the monolith...
And here's where things get messy. How do you extract Module A as an independent service when it's tightly coupled at the
database level with the IAM module? If we remove the join to the IAM tables, access control will
stop working.
Below, I'll present techniques that will allow us to extract this module from the monolith without losing functionality, breaking modularization rules, or changing dependencies between modules.
When designing a modular monolith, it's worth trying a slightly different approach. Instead of prefixing tables, you can create separate databases/schemas for each module within a single database server, which makes it much harder to create accidental coupling at the SQL query level.
Division of Responsibility
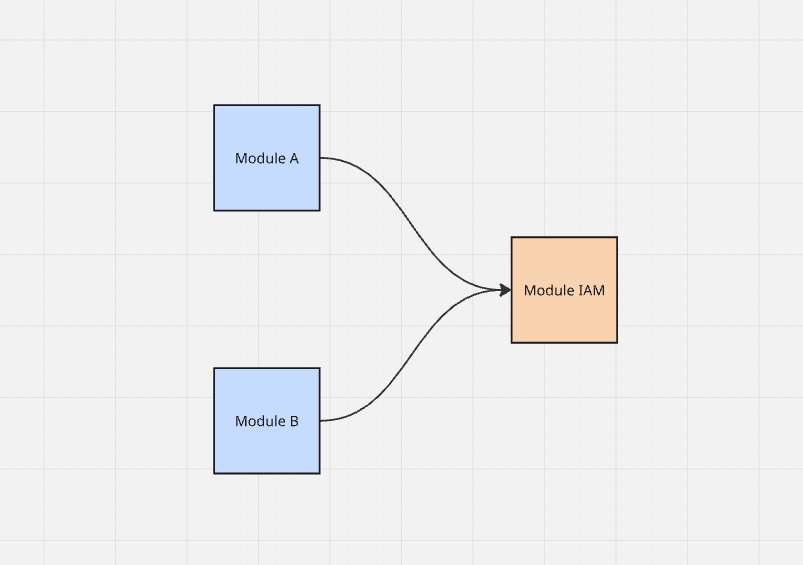
What if it wasn't the IAM module that was responsible for permissions granted to resources
that only exist in a specific module?
One possible approach (probably the best for many) is separation of responsibilities, meaning IAM
handles authorization, users, their roles, and the groups they're assigned to.
The modules themselves manage the permission rules for resources. In practice, this means moving the access_rules tables
to Module A and Module B.
The result would be an architecture similar to the one below:
None of the modules need to make trips to IAM to get a list of resources available
to a selected user.
We do have some duplication - we basically need to repeat the permission logic for each existing module and hook it into the existing module mechanisms.
Note: Here you might be tempted to create a component. Unless you have people on your teams who are experienced in building libraries/components, it's best to start with duplication. In the long run, duplication hurts way less than the wrong abstraction.
But is that enough?
Not quite. If we look at the permissions table, we'll notice that permissions can be granted directly to a user or to a group that the user belongs to.
This means that in Module A, we grant permissions to a resource for group Group 01, which includes
User 01 and User 02.
Thanks to this, both users have access to the resource.
But what if we remove a user from the selected group?
We can approach this in two ways:
- During each access verification, we query the
IAMmodule for the user's list of groups - We accept
eventual consistencyand keep user groups in the session, refreshing it every few/dozen minutes
The first solution is simplest to implement, doesn't violate module responsibility boundaries, but might become a bottleneck pretty quickly.
Of course, this won't happen immediately. Plus, due to the nature of the data (more reads than writes), we can also offload the database through appropriate caching mechanisms.
For solution number two, we need to make sure this is even an acceptable solution from a business perspective.
Projection
Another approach to solving the problem is keeping the permission structure in the IAM module but
introducing mechanisms that allow Module A and Module B to sync
the permissions table to a local projection.
This projection is nothing more than a simplified form of the access_rules table replicated in a specific module.
As a result, we still get some duplication, but Module A and Module B
don't focus on managing permissions - that responsibility is still delegated to the IAM module.
Their responsibility is reduced to syncing permissions with the permissions module.
But how and when do we perform this sync? Every time we grant permissions to a resource.
Module A, when granting permissions to a user or group for some resource, first
communicates with the IAM module.
We do the same when revoking access to a resource. First, we remove the entry in the IAM module, then
we remove the entry in the local projection.
But what if we remove a user from a selected group?
Here we basically return to the same problem we had in the previous approach. We can either
fetch the user's list of groups from the IAM module each time, or accept eventual consistency.
The difference between separation and projection is very small. But with projections, we can take it a step further.
Events
The IAM module can also propagate events related to:
- Adding a user to groups
- Removing a user from a group
- Deleting a group
To maintain the proper dependency structure, these events can't be published "to a specific recipient."
We need to apply a Pub/Sub approach here, where IAM publishes events to a specific
Topic, which interested modules can subscribe to.
Thanks to this, both modules will receive a copy of the same event, which they can handle independently.
When building a projection, we can also significantly simplify its structure by breaking down groups into user lists.
If a group receives access permission to some resource, instead of storing
one entry in the projection representing the group, we can create an entry for each user in the group.
Thanks to this, during access verification, we don't need to ask the IAM module for anything at all. We just need to
respond appropriately to events propagated by the IAM module:
- Adding a user to a group
- Removing a user from a group
- Deleting a group
Basically, only these events matter to us. Adding a group or user doesn't really affect anything, so we can safely ignore/filter them out.
Event Reliability
Of course, an event-based approach carries certain risks. One of them is, for example, disrupted event order.
For instance, we first get a "user removed from group" event, and only later the "user added" event, when
in reality these events occurred in the opposite order.
Yeah, this can be a problem, especially when the message containing the event also includes all the details of that event.
But we can deal with this by deciding to use anemic events - that is, events that basically only contain identifiers of the resources they concern, and for everything else you need to go to the source module.
Let's compare both approaches using the UserRemovedFromGroup event as an example:
Rich Event
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"userName": "jan.kowalski",
"userEmail": "[email protected]",
"groupId": 456,
"groupName": "Administrators",
"groupPermissions": ["read", "write", "delete"],
"removedBy": {
"userId": 789,
"userName": "admin"
}
}
}
Anemic Event
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"groupId": 456
}
}
The difference is fundamental. With a rich event, all information about the user, group, and permissions is contained in the event. If the order of events gets disrupted, our projection can end up in an inconsistent state.
An anemic event, on the other hand, only contains identifiers. After receiving such an event, the consumer must
make an additional query to the IAM module to get the current state. Thanks to this, regardless of the order
events are received, we'll always get the most up-to-date version of the data.
Problematic Scenario for Rich Events
Let's imagine the following sequence of events in the IAM module:
10:00:00- User added to "Administrators" group10:00:05- User removed from "Administrators" group
The consumer in Module A receives events in reverse order:
- Receives
UserRemovedFromGroup(with data from 10:00:05) - Receives
UserAddedToGroup(with data from 10:00:00)
With rich events, the projection in Module A shows that the user belongs to the group (because the last received event was "addition"), even though in reality they've already been removed from it.
With anemic events, regardless of the order received, Module A will execute a query to IAM and get the current state - the user doesn't belong to the group.
Anemic events reduce the risk of inconsistency but don't eliminate it completely. There's still the possibility that between receiving the event and querying IAM, the state changes. So you might consider adding a version number or timestamp to events and checking them when updating the projection. Though safeguarding mechanisms will largely depend on traffic and frequency of changes.
Here's what it looks like:
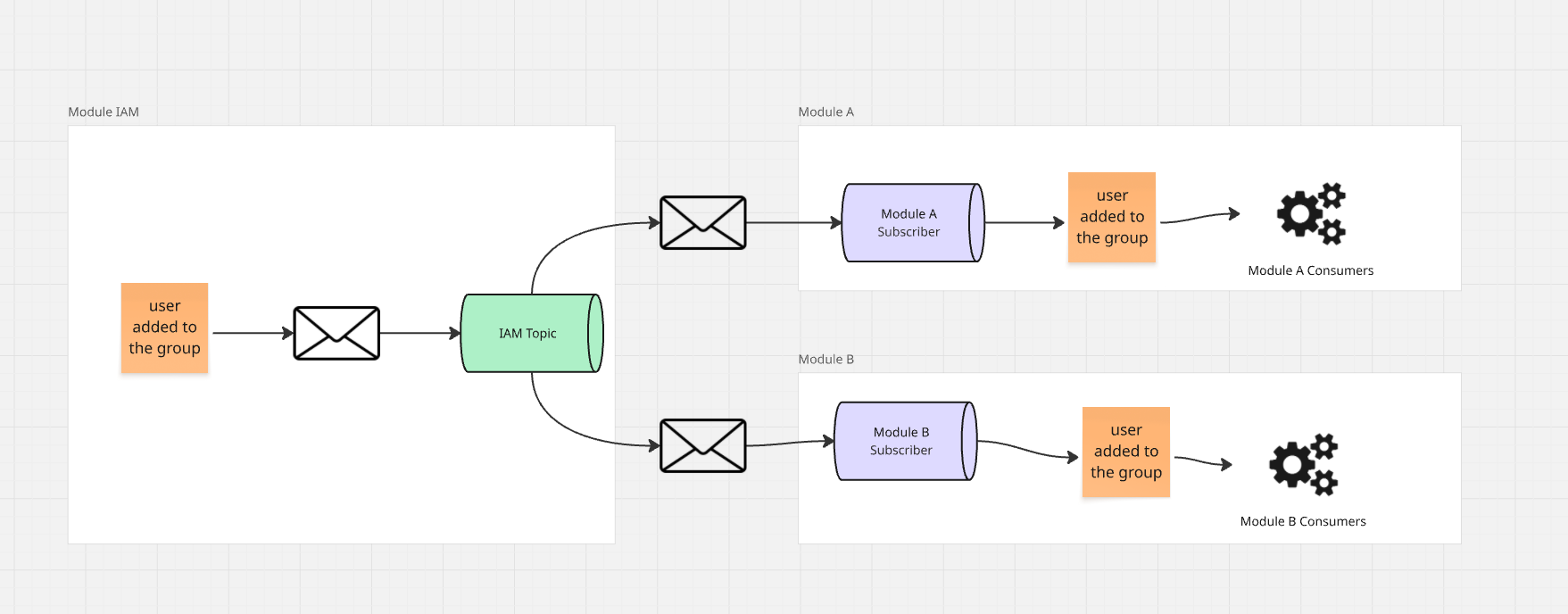
When Module A's consumer receives information, its job is to go to the IAM module and ask it
for all rules for a specific group. The IAM module can return records from the permissions table concerning
a specific group, and then, if any rules exist, we can ask for users in that group and in
the module's local projection build a permission projection for them.
We can also make life a bit easier for ourselves and add to the communication protocol with the IAM module the ability to
fetch a flat structure of permissions, which returns not the group but a list of group users with permissions to
a specific resource.
Note: To provide additional guarantees of event delivery, consider implementing the Outbox pattern.
Wait, but won't the IAM module become a bottleneck again?
Not exactly. What matters here isn't just the query itself but rather its frequency. Permission control is one of those processes where we ask about permissions way more often than we change them.
Of course, don't just take my word for it - if you have an existing system with permission control, it's worth simply measuring it.
But getting back to the point, when using anemic events, we don't have to worry as much about the order they're received. We're not relying on the event's content but only on the resource identifier it concerns, which makes building projections much easier.
But this does have its cost - now after each event we need to go to the source to determine the actual state.
So it's worth analyzing this approach from a performance perspective.
There are more techniques for dealing with events, though. You can find one at https://event-driven.io/.
Duplication
In both approaches, though, the problem of duplication comes up. Although in this case, "problem" is probably the wrong word. It's just a cost of modularization that simply isn't talked about.
Regardless of whether we decide on separation of responsibilities or building projections, Modules A and B will duplicate permission-related logic to a greater or lesser extent.
So regardless of our deployment model (monolith / microservices) and regardless of how we separate module boundaries and their responsibilities, we just need to prepare for this cost.
My advice here is always to start with duplication. Even if our implementations don't differ at all between modules.
It's much easier to extract common parts from existing solutions than to design common parts for solutions that don't exist yet.
What's Better?
There's no clear-cut answer to this question. But we can try to analyze our situation and choose a solution that will let us extract one of the modules and get rid of database-level coupling.
For the module that needs to be extracted, I'd suggest (if possible) separation of responsibilities and moving resource permission management to that module.
Since we have to do some work anyway, since we have to physically separate this module from our monolith,
we might as well go a step further and reduce its dependency on
IAM even more at a relatively low cost.
But does such an operation make sense for existing modules?
For modules that don't need to be extracted and will continue living within the modular monolith, I'd suggest a projection-based approach, but not necessarily with events.
Projections Without Events
This is a technique that won't work in a microservices approach but can help as a stopgap. Not just help, but also point the way forward. You can implement it at a low cost, getting basically the same thing as with an event-based approach.
Let's look at it from a different angle. Pub/Sub is basically a mechanism that allows us a certain form of replication. Thanks to events, we know that something happened at some point in some module.
What if instead of publishing an event to a Topic, we used Materialized Views?
Yeah, I know - many people are probably seeing red flags right now. I mean, materialized views? Logic on the database side instead of in code?
Well, it's not an ideal solution. Sure, we get rid of SQL-level coupling, but in exchange we get different coupling - this time at the database level.
But if we approach this pragmatically, we're basically just swapping the transport mechanism. Instead of building pub/sub, implementing the Outbox pattern, handling network communication errors, retries, etc., we can just let the database handle data replication.
If for any reason this stops working for us - like when refreshing the materialized view becomes too expensive and starts unnecessarily loading our database - nothing will stop us from switching to projections.
But before we get to that point, we can also try putting the refresh process itself on a queue in the IAM module
and executing it asynchronously. We'll get a slight delay, though in this case it should be at an acceptable level.
The key thing to understand is that a Materialized View isn't a bad or good solution - it just gives us
the ability to introduce a simplified separation relatively quickly without having to build the entire event-based mechanism.
But when full separation/performance/vendor locking or anything else starts bothering us here, there shouldn't be major problems switching to projections.
That's exactly what makes Materialized View an interesting solution.
The Ideal Solution
Doesn't exist...
And that's probably the most important thing I want to get across in this article.
Even if we manage to reduce the problem purely to technology, and even if by some miracle we all agree that problem A should be solved with pattern/technique/architecture B...
None of that might matter because the business might simply not approve a major refactoring...
And this doesn't have to be bad faith or ignorance - sometimes we just don't have the resources.
It's hard to justify why we should spend time moving permission management to modules when everything works and generates profit.
Just as hard as it'll be to argue why suddenly, with a requirement to extract one module, we have to fix all the others, adding asynchronous communication, events, retry mechanisms, recovery, etc.
It's worth accepting that the world isn't perfect, isn't black and white, and we'll often have to choose between several imperfect solutions.
What might seem absolutely incorrect in one place could be acceptable in another context, or even desirable.
Help
If you're struggling with similar problems in your project and aren't quite sure how to solve them,
get in touch with me, and together we'll find a solution perfectly tailored to your needs.
I also encourage you to visit Discord - Flow PHP, where we can talk directly.
