
Die dunklen Seiten der Modularisierung
Einführung
Ich bin kürzlich auf ein ziemlich interessantes Problem gestoßen, das mich zum Nachdenken über die weniger verlockenden Aspekte der Modularisierung gebracht hat - Sie wissen schon, die Dinge, über die wir normalerweise nicht auf Konferenzen oder Workshops sprechen.
Fangen wir bei den Grundlagen an. Was genau ist Modularisierung? Einfach ausgedrückt: Es ist die Aufteilung eines Systems in unabhängige Teile (Module), von denen jedes:
- Eine klar definierte Verantwortlichkeit hat
- Über definierte Protokolle kommuniziert
- Unabhängig von anderen Modulen entwickelt werden kann
Kurz gesagt, es ist eine Verbeugung vor dem Prinzip Teile und herrsche. Anstatt mit einem massiven, komplizierten, verworrenen Problem zu kämpfen, teilen wir es in kleinere Probleme auf, die viel einfacher zu lösen sind.
Viele Leute hören "Modularisierung" und denken sofort an "Microservices". Lassen Sie uns also eine Sache klarstellen, bevor wir weitermachen. Microservices sind nur eine Möglichkeit, Modularisierung zu implementieren, genau wie ein modularer Monolith.
Der aktuelle Zustand
Stellen Sie sich ein System vor, das aus drei Modulen besteht.
Hinweis: Das untenstehende Diagramm ist ein sehr vereinfachtes Modell - sein einziger Zweck ist es, das Problem zu veranschaulichen.
IAM-Modul (Identity and Access) - Benutzer / Gruppen / BerechtigungenModul A- RessourcenverwaltungModul B- andere Ressourcenverwaltung
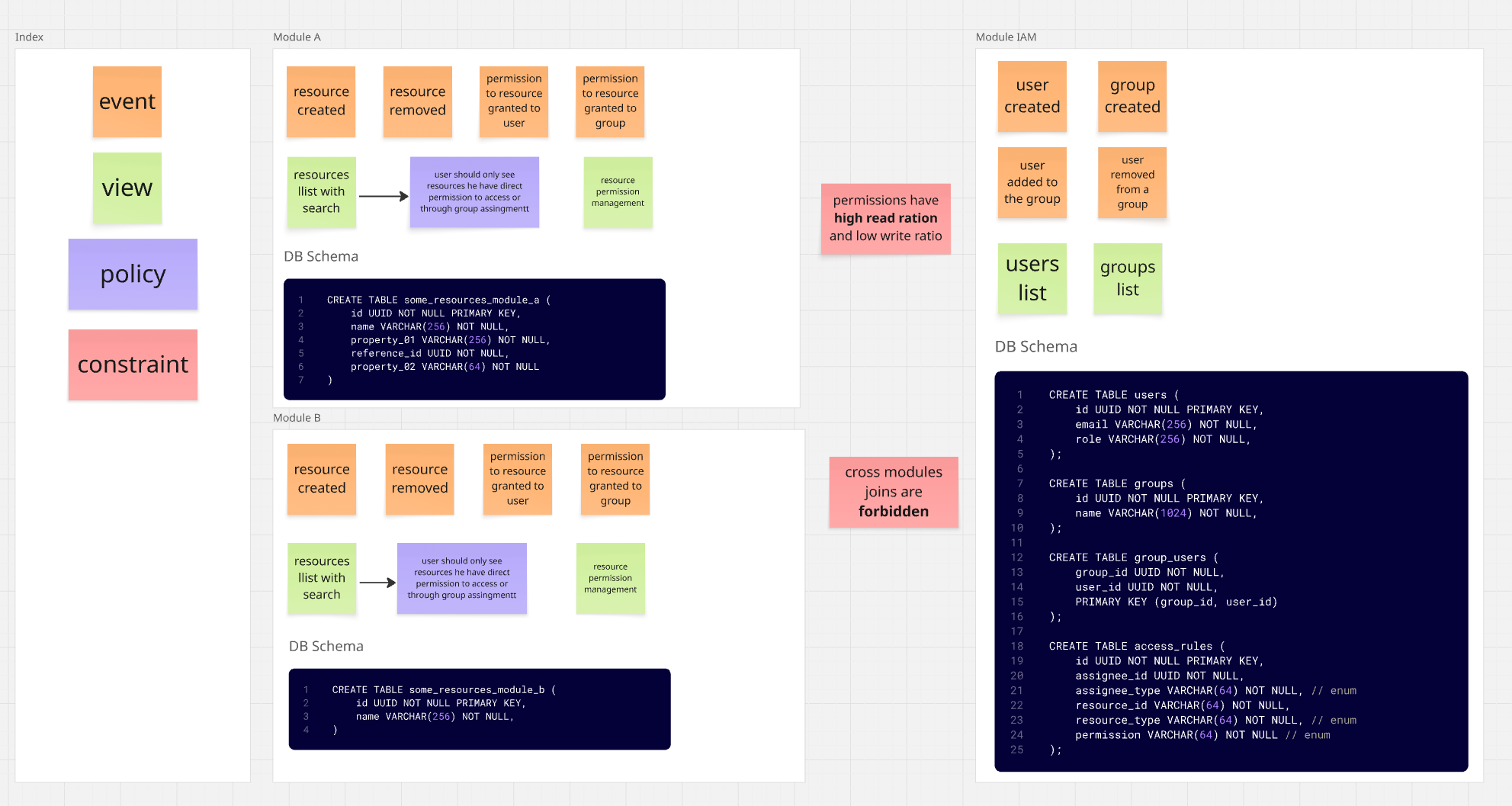
Das Berechtigungssystem hier ist etwas komplex. Es basiert hauptsächlich auf ACL (Access Control List),
was bedeutet, dass Berechtigungen für Ressourcen direkt an Benutzer oder Gruppen vergeben werden.
Darüber hinaus gibt es auch etwas RBAC (Role Based Access Control), bei dem Benutzer mit bestimmten
Rollen definierte Berechtigungen für bestimmte Teile des Systems haben.
Wir haben auch teilweise ABAC (Attribute Based Access Control), bei dem Berechtigungen aus Benutzerattributen abgeleitet werden,
in diesem Fall aus der Gruppenmitgliedschaft.
Kommt Ihnen das bekannt vor? Dies ist kein so einzigartiger Fall, wie Sie vielleicht denken. Aber jedenfalls, kommen wir zum Punkt.
Das Problem
Wie Sie im Diagramm sehen können, ist das Berechtigungssystem im IAM-Modul definiert - dort speichern wir
Informationen über:
- Benutzer und ihre Rollen
- Gruppen, zu denen Benutzer gehören
- Berechtigungen für bestimmte Ressourcen
Module A und B sind in der Zwischenzeit für die Verwaltung ihrer eigenen Ressourcen verantwortlich, müssen aber überprüfen, ob ein bestimmter Benutzer Zugriff auf eine bestimmte Ressource hat.
Das Modulabhängigkeitsschema sieht also so aus: Module A und B wissen von der Existenz des IAM-Moduls (sie sind davon abhängig), aber das IAM-Modul selbst hat keine Ahnung, dass Module A und B existieren.
Das Problem, auf das das Team gestoßen ist, war folgendes: "Wie erstellen wir eine paginierte Liste von Ressourcen in einem bestimmten Modul basierend auf Benutzerberechtigungen?"
Zusätzlich muss die Ressourcenliste Folgendes ermöglichen:
- Filterung basierend auf Ressourcenmerkmalen
- Sortierung basierend auf Ressourcenmerkmalen
- Rückgabe nur einer ausgewählten Seite
Diese Anforderungen machen die Implementierung erheblich schwieriger. Wenn wir keine Filterung/Paginierung hätten, könnten wir einfach
das IAM-Modul direkt mit einer Anfrage ansprechen, Ressourcen für einen bestimmten Benutzer zurückzugeben.
Ressourcenmerkmale sind all ihre Parameter und Attribute, die hauptsächlich innerhalb ihres
eigenen Kontexts Sinn und Bedeutung haben. Beispielhafte Ressourcenmerkmale könnten ihr Name oder das Erstellungsdatum sein. Dies sind Parameter, nach denen
der Benutzer sortieren oder filtern können sollte, die aber nicht im IAM-Modul existieren.
Aber ohne Ressourcenmerkmale, nach denen wir filtern/sortieren können, kann das IAM-Modul bestenfalls alle Ressourcen zurückgeben,
und wir müssten die Filterung auf der Modulseite durchführen. Keine besonders skalierbare Lösung.
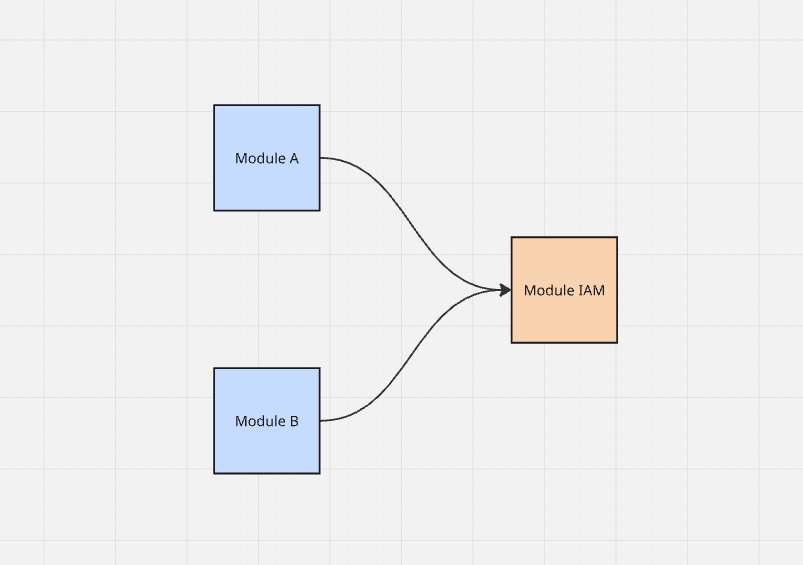
Da das Team nicht wusste, wie es aus dieser Situation herauskommen sollte, beschloss es (bewusst oder unbewusst), die Regeln der Modularisierung zu brechen und die Module auf Datenbankebene zu koppeln.
Da das System als modularer Monolith bereitgestellt wird und jedes Modul Zugriff auf dieselbe Datenbank hat (jedes Modul hat seine eigenen Tabellen mit entsprechendem Präfix),
steht theoretisch nichts im Wege, eine SQL-Abfrage zu erstellen, die eine Liste von Ressourcen für ein bestimmtes Modul zurückgibt
und sie mit Berechtigungstabellen aus dem IAM-Modul zu verbinden, um Ressourcen herauszufiltern, auf die der Benutzer keinen Zugriff hat.
Schnell, einfach und es funktioniert sogar.
Dies könnte wahrscheinlich friedlich koexistieren, außer es gibt eine neue Anforderung: Wir müssen eines der Module aus dem Monolithen extrahieren...
Und hier wird es chaotisch. Wie extrahiert man Modul A als unabhängigen Service, wenn es auf
Datenbankebene eng mit dem IAM-Modul gekoppelt ist? Wenn wir den Join zu den IAM-Tabellen entfernen, wird die Zugriffskontrolle
nicht mehr funktionieren.
Im Folgenden werde ich Techniken vorstellen, die es uns ermöglichen, dieses Modul aus dem Monolithen zu extrahieren, ohne Funktionalität zu verlieren, Modularisierungsregeln zu brechen oder Abhängigkeiten zwischen Modulen zu ändern.
Beim Entwurf eines modularen Monolithen lohnt es sich, einen etwas anderen Ansatz zu versuchen. Anstatt Tabellen zu präfixieren, können Sie separate Datenbanken/Schemas für jedes Modul innerhalb eines einzelnen Datenbankservers erstellen, was es viel schwieriger macht, versehentliche Kopplungen auf SQL-Abfrageebene zu erstellen.
Trennung der Verantwortlichkeiten
Was wäre, wenn nicht das IAM-Modul für Berechtigungen verantwortlich wäre, die für Ressourcen vergeben werden,
die nur in einem bestimmten Modul existieren?
Ein möglicher Ansatz (wahrscheinlich der beste für viele) ist die Trennung von Verantwortlichkeiten, was bedeutet, dass IAM
die Autorisierung, Benutzer, ihre Rollen und die Gruppen übernimmt, denen sie zugewiesen sind.
Die Module selbst verwalten die Berechtigungsregeln für Ressourcen. In der Praxis bedeutet dies, die access_rules-Tabellen
nach Modul A und Modul B zu verschieben.
Das Ergebnis wäre eine Architektur ähnlich der folgenden:
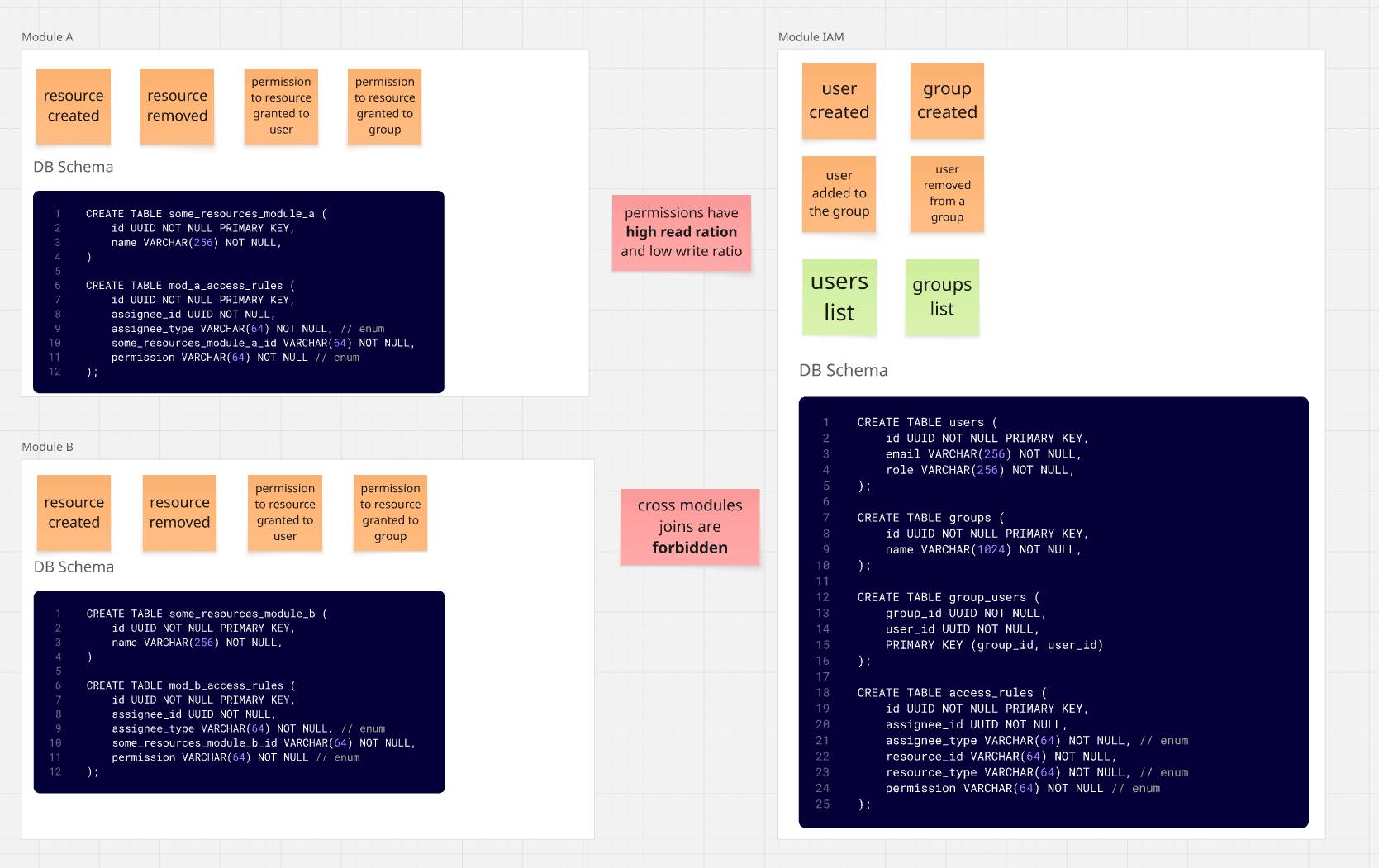
Keines der Module muss Ausflüge zu IAM machen, um eine Liste von Ressourcen zu erhalten, die
einem ausgewählten Benutzer zur Verfügung stehen.
Wir haben zwar einige Duplikate - wir müssen im Grunde die Berechtigungslogik für jedes vorhandene Modul wiederholen und sie in die vorhandenen Modulmechanismen einbinden.
Hinweis: Hier könnten Sie versucht sein, eine Komponente zu erstellen. Es sei denn, Sie haben Leute in Ihren Teams, die Erfahrung im Erstellen von Bibliotheken/Komponenten haben, ist es am besten, mit Duplikation zu beginnen. Auf lange Sicht schmerzt Duplikation viel weniger als die falsche Abstraktion.
Aber reicht das aus?
Nicht ganz. Wenn wir uns die Berechtigungstabelle ansehen, werden wir feststellen, dass Berechtigungen direkt einem Benutzer oder einer Gruppe, zu der der Benutzer gehört, erteilt werden können.
Das bedeutet, dass wir in Modul A Berechtigungen für eine Ressource für Gruppe Gruppe 01 erteilen, die
Benutzer 01 und Benutzer 02 umfasst.
Dadurch haben beide Benutzer Zugriff auf die Ressource.
Aber was ist, wenn wir einen Benutzer aus der ausgewählten Gruppe entfernen?
Wir können dies auf zwei Arten angehen:
- Bei jeder Zugriffsüberprüfung fragen wir das
IAM-Modul nach der Liste der Gruppen des Benutzers - Wir akzeptieren
Eventual Consistencyund behalten Benutzergruppen in der Sitzung, die wir alle paar/Dutzend Minuten aktualisieren
Die erste Lösung ist am einfachsten zu implementieren, verletzt keine Modulverantwortlichkeitsgrenzen, könnte aber ziemlich schnell zu einem Flaschenhals werden.
Natürlich wird dies nicht sofort passieren. Außerdem können wir aufgrund der Art der Daten (mehr Lesezugriffe als Schreibzugriffe) die Datenbank auch durch entsprechende Caching-Mechanismen entlasten.
Für Lösung Nummer zwei müssen wir sicherstellen, dass dies überhaupt eine akzeptable Lösung aus geschäftlicher Sicht ist.
Projektion
Ein weiterer Ansatz zur Lösung des Problems besteht darin, die Berechtigungsstruktur im IAM-Modul beizubehalten, aber
Mechanismen einzuführen, die es Modul A und Modul B ermöglichen, die
Berechtigungstabelle mit einer lokalen Projektion zu synchronisieren.
Diese Projektion ist nichts anderes als eine vereinfachte Form der access_rules-Tabelle, die in einem bestimmten Modul repliziert wird.
Als Ergebnis erhalten wir immer noch eine gewisse Duplikation, aber Modul A und Modul B
konzentrieren sich nicht auf die Verwaltung von Berechtigungen - diese Verantwortung ist immer noch dem IAM-Modul übertragen.
Ihre Verantwortung reduziert sich auf die Synchronisierung von Berechtigungen mit dem Berechtigungsmodul.
Aber wie und wann führen wir diese Synchronisierung durch? Jedes Mal, wenn wir Berechtigungen für eine Ressource erteilen.
Modul A kommuniziert beim Erteilen von Berechtigungen an einen Benutzer oder eine Gruppe für eine Ressource zuerst
mit dem IAM-Modul.
Wir machen dasselbe beim Widerrufen des Zugriffs auf eine Ressource. Zuerst entfernen wir den Eintrag im IAM-Modul, dann
entfernen wir den Eintrag in der lokalen Projektion.
Was ist aber, wenn wir einen Benutzer aus einer ausgewählten Gruppe entfernen?
Hier kehren wir im Grunde zum selben Problem zurück, das wir beim vorherigen Ansatz hatten. Wir können entweder
jedes Mal die Liste der Gruppen des Benutzers aus dem IAM-Modul abrufen oder Eventual Consistency akzeptieren.
Der Unterschied zwischen Trennung und Projektion ist sehr gering. Mit Projektionen können wir jedoch einen Schritt weiter gehen.
Ereignisse
Das IAM-Modul kann auch Ereignisse im Zusammenhang mit:
- Hinzufügen eines Benutzers zu Gruppen
- Entfernen eines Benutzers aus einer Gruppe
- Löschen einer Gruppe
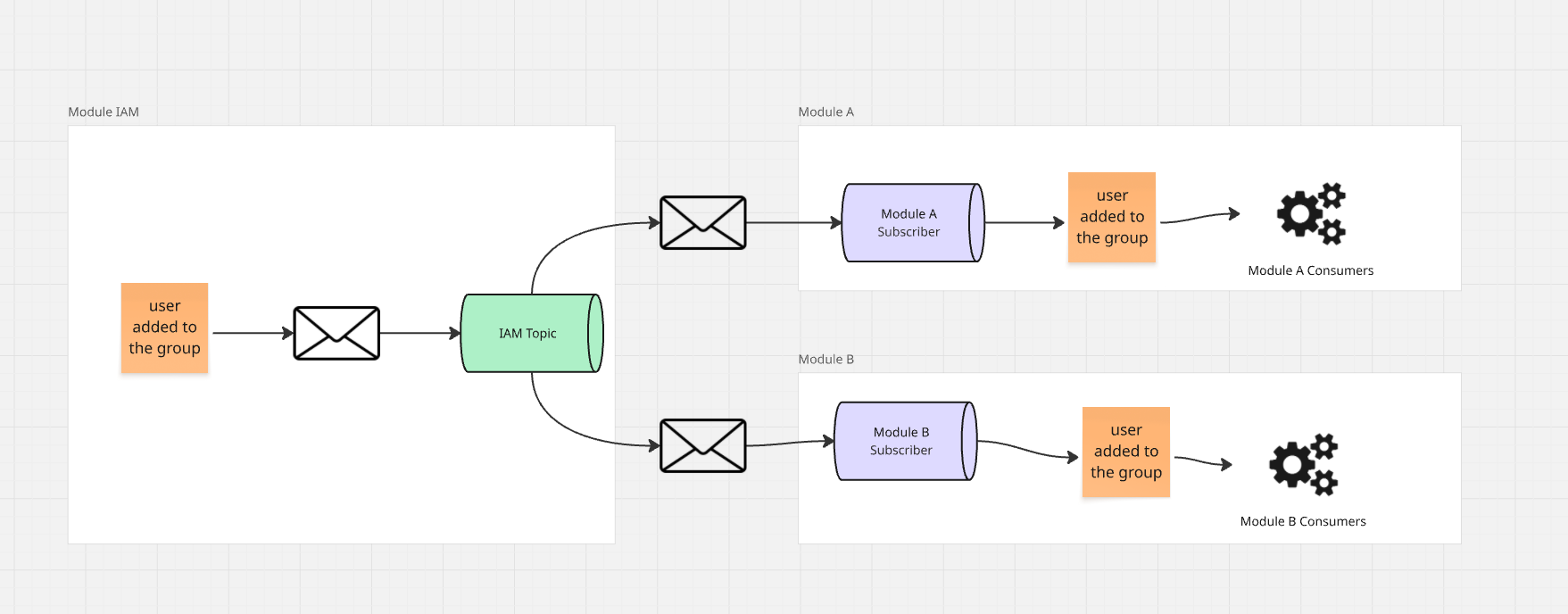
Um die richtige Abhängigkeitsstruktur aufrechtzuerhalten, können diese Ereignisse nicht "an einen bestimmten Empfänger" veröffentlicht werden.
Wir müssen hier einen Pub/Sub-Ansatz anwenden, bei dem IAM Ereignisse zu einem bestimmten
Topic veröffentlicht, das interessierte Module abonnieren können.
Dadurch erhalten beide Module eine Kopie desselben Ereignisses, das sie unabhängig verarbeiten können.
Beim Erstellen einer Projektion können wir auch ihre Struktur erheblich vereinfachen, indem wir Gruppen in Benutzerlisten aufteilen.
Wenn eine Gruppe Zugriffsberechtigung auf eine Ressource erhält, können wir anstatt
einen Eintrag in der Projektion zu speichern, der die Gruppe repräsentiert, einen Eintrag für jeden Benutzer in der Gruppe erstellen.
Dadurch müssen wir bei der Zugriffsüberprüfung das IAM-Modul überhaupt nicht nach etwas fragen. Wir müssen nur
entsprechend auf Ereignisse reagieren, die vom IAM-Modul propagiert werden:
- Hinzufügen eines Benutzers zu einer Gruppe
- Entfernen eines Benutzers aus einer Gruppe
- Löschen einer Gruppe
Im Grunde sind nur diese Ereignisse für uns wichtig. Das Hinzufügen einer Gruppe oder eines Benutzers hat eigentlich keine Auswirkungen, daher können wir sie sicher ignorieren/herausfiltern.
Ereigniszuverlässigkeit
Natürlich birgt ein ereignisbasierter Ansatz gewisse Risiken. Eines davon ist zum Beispiel eine gestörte Ereignisreihenfolge.
Zum Beispiel erhalten wir zuerst ein Ereignis "Benutzer aus Gruppe entfernt" und erst später das Ereignis "Benutzer hinzugefügt", obwohl
diese Ereignisse in Wirklichkeit in umgekehrter Reihenfolge aufgetreten sind.
Ja, das kann ein Problem sein, besonders wenn die Nachricht, die das Ereignis enthält, auch alle Details dieses Ereignisses enthält.
Aber wir können damit umgehen, indem wir uns entscheiden, anemische Ereignisse zu verwenden - das heißt, Ereignisse, die im Grunde nur Identifikatoren der betroffenen Ressourcen enthalten, und für alles andere müssen Sie zum Quellmodul gehen.
Vergleichen wir beide Ansätze am Beispiel des UserRemovedFromGroup-Ereignisses:
Reichhaltiges Ereignis (Rich Event)
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"userName": "jan.kowalski",
"userEmail": "[email protected]",
"groupId": 456,
"groupName": "Administrators",
"groupPermissions": ["read", "write", "delete"],
"removedBy": {
"userId": 789,
"userName": "admin"
}
}
}
Anemisches Ereignis (Anemic Event)
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"groupId": 456
}
}
Der Unterschied ist grundlegend. Bei einem reichhaltigen Ereignis sind alle Informationen über den Benutzer, die Gruppe und die Berechtigungen im Ereignis enthalten. Wenn die Reihenfolge der Ereignisse gestört wird, kann unsere Projektion in einem inkonsistenten Zustand enden.
Ein anemisches Ereignis hingegen enthält nur Identifikatoren. Nach Erhalt eines solchen Ereignisses muss der Consumer
eine zusätzliche Abfrage an das IAM-Modul stellen, um den aktuellen Zustand zu erhalten. Dadurch erhalten wir unabhängig von der Reihenfolge,
in der Ereignisse empfangen werden, immer die aktuellste Version der Daten.
Problematisches Szenario für reichhaltige Ereignisse
Stellen wir uns die folgende Ereignissequenz im IAM-Modul vor:
10:00:00- Benutzer zur Gruppe "Administrators" hinzugefügt10:00:05- Benutzer aus Gruppe "Administrators" entfernt
Der Consumer in Modul A empfängt Ereignisse in umgekehrter Reihenfolge:
- Empfängt
UserRemovedFromGroup(mit Daten von 10:00:05) - Empfängt
UserAddedToGroup(mit Daten von 10:00:00)
Bei reichhaltigen Ereignissen zeigt die Projektion in Modul A, dass der Benutzer zur Gruppe gehört (weil das zuletzt empfangene Ereignis "Hinzufügen" war), obwohl er in Wirklichkeit bereits daraus entfernt wurde.
Bei anemischen Ereignissen führt Modul A unabhängig von der Empfangsreihenfolge eine Abfrage an IAM aus und erhält den aktuellen Zustand - der Benutzer gehört nicht zur Gruppe.
Anemische Ereignisse reduzieren das Risiko von Inkonsistenzen, eliminieren es aber nicht vollständig. Es besteht immer noch die Möglichkeit, dass sich zwischen dem Empfang des Ereignisses und der Abfrage an IAM der Zustand ändert. Sie könnten also erwägen, eine Versionsnummer oder einen Zeitstempel zu Ereignissen hinzuzufügen und diese beim Aktualisieren der Projektion zu überprüfen. Obwohl Sicherheitsmechanismen größtenteils vom Datenverkehr und der Änderungshäufigkeit abhängen werden.
So sieht es aus:
Wenn der Consumer von Modul A Informationen erhält, besteht seine Aufgabe darin, zum IAM-Modul zu gehen und es
nach allen Regeln für eine bestimmte Gruppe zu fragen. Das IAM-Modul kann Datensätze aus der Berechtigungstabelle zurückgeben, die eine
bestimmte Gruppe betreffen, und dann können wir, wenn Regeln vorhanden sind, nach Benutzern in dieser Gruppe fragen und in
der lokalen Projektion des Moduls eine Berechtigungsprojektion für sie erstellen.
Wir können uns das Leben auch etwas einfacher machen und dem Kommunikationsprotokoll mit dem IAM-Modul die Möglichkeit hinzufügen,
eine flache Struktur von Berechtigungen abzurufen, die nicht die Gruppe, sondern eine Liste von Gruppenbenutzern mit Berechtigungen für
eine bestimmte Ressource zurückgibt.
Hinweis: Um zusätzliche Garantien für die Ereigniszustellung zu bieten, sollten Sie erwägen, das Outbox-Muster zu implementieren.
Warten Sie, aber wird das IAM-Modul nicht wieder zu einem Flaschenhals?
Nicht ganz. Was hier wichtig ist, ist nicht nur die Abfrage selbst, sondern vielmehr ihre Häufigkeit. Berechtigungskontrolle ist einer dieser Prozesse, bei denen wir viel häufiger nach Berechtigungen fragen als sie zu ändern.
Natürlich glauben Sie mir nicht einfach - wenn Sie ein bestehendes System mit Berechtigungskontrolle haben, lohnt es sich, dies einfach zu messen.
Aber um auf den Punkt zu kommen: Bei der Verwendung anemischer Ereignisse müssen wir uns nicht so sehr um die Reihenfolge ihres Empfangs sorgen. Wir verlassen uns nicht auf den Inhalt des Ereignisses, sondern nur auf die Ressourcen-ID, die es betrifft, was das Erstellen von Projektionen viel einfacher macht.
Dies hat jedoch seinen Preis - jetzt müssen wir nach jedem Ereignis zur Quelle gehen, um den tatsächlichen Zustand zu ermitteln.
Es lohnt sich also, diesen Ansatz aus Performance-Sicht zu analysieren.
Es gibt jedoch mehr Techniken für den Umgang mit Ereignissen. Eine davon finden Sie auf https://event-driven.io/.
Duplikation
In beiden Ansätzen taucht jedoch das Problem der Duplikation auf. Obwohl in diesem Fall "Problem" wahrscheinlich das falsche Wort ist. Es sind einfach Kosten der Modularisierung, über die einfach nicht gesprochen wird.
Unabhängig davon, ob wir uns für eine Trennung der Verantwortlichkeiten oder den Aufbau von Projektionen entscheiden, werden Module A und B die berechtigungsbezogene Logik mehr oder weniger duplizieren.
Unabhängig von unserem Bereitstellungsmodell (Monolith / Microservices) und unabhängig davon, wie wir Modulgrenzen und ihre Verantwortlichkeiten trennen, müssen wir uns einfach auf diese Kosten vorbereiten.
Mein Rat hier ist immer, mit Duplikation zu beginnen. Selbst wenn sich unsere Implementierungen überhaupt nicht zwischen Modulen unterscheiden.
Es ist viel einfacher, gemeinsame Teile aus bestehenden Lösungen zu extrahieren, als gemeinsame Teile für Lösungen zu entwerfen, die noch nicht existieren.
Was ist besser?
Auf diese Frage gibt es keine eindeutige Antwort. Aber wir können versuchen, unsere Situation zu analysieren und eine Lösung zu wählen, die es uns ermöglicht, eines der Module zu extrahieren und die Kopplung auf Datenbankebene loszuwerden.
Für das Modul, das extrahiert werden muss, würde ich (wenn möglich) eine Trennung der Verantwortlichkeiten vorschlagen und die Verwaltung von Ressourcenberechtigungen in dieses Modul verschieben.
Da wir sowieso etwas Arbeit leisten müssen, da wir dieses Modul physisch von unserem Monolithen trennen müssen,
können wir auch einen Schritt weiter gehen und seine Abhängigkeit von
IAM zu relativ geringen Kosten noch weiter reduzieren.
Aber macht eine solche Operation für bestehende Module Sinn?
Für Module, die nicht extrahiert werden müssen und weiterhin innerhalb des modularen Monolithen leben werden, würde ich einen projektionsbasierten Ansatz vorschlagen, aber nicht unbedingt mit Ereignissen.
Projektionen ohne Ereignisse
Dies ist eine Technik, die bei einem Microservices-Ansatz nicht funktioniert, aber als Übergangslösung helfen kann. Nicht nur helfen, sondern auch den Weg nach vorne weisen. Sie können sie zu geringen Kosten implementieren und erhalten im Grunde dasselbe wie bei einem ereignisbasierten Ansatz.
Betrachten wir es aus einem anderen Blickwinkel. Pub/Sub ist im Grunde ein Mechanismus, der uns eine bestimmte Form der Replikation ermöglicht. Dank Ereignissen wissen wir, dass zu einem bestimmten Zeitpunkt in einem bestimmten Modul etwas passiert ist.
Was wäre, wenn wir anstatt ein Ereignis zu einem Topic zu veröffentlichen, Materialized Views verwenden würden?
Ja, ich weiß - viele Leute sehen wahrscheinlich gerade rote Flaggen. Ich meine, Materialized Views? Logik auf der Datenbankseite statt im Code?
Nun, es ist keine ideale Lösung. Sicher, wir werden die SQL-Ebenen-Kopplung los, aber im Austausch erhalten wir eine andere Kopplung - diesmal auf Datenbankebene.
Aber wenn wir das pragmatisch angehen, tauschen wir im Grunde nur den Transportmechanismus aus. Anstatt Pub/Sub aufzubauen, das Outbox-Muster zu implementieren, Netzwerkkommunikationsfehler zu behandeln, Wiederholungen usw., können wir einfach die Datenbank die Datenreplikation übernehmen lassen.
Wenn dies aus irgendeinem Grund nicht mehr für uns funktioniert - wie wenn das Aktualisieren der Materialized View zu teuer wird und unsere Datenbank unnötig belastet - wird uns nichts daran hindern, zu Projektionen zu wechseln.
Aber bevor wir diesen Punkt erreichen, können wir auch versuchen, den Aktualisierungsprozess selbst in eine Warteschlange im IAM-Modul zu stellen
und ihn asynchron auszuführen. Wir erhalten eine leichte Verzögerung, die in diesem Fall jedoch auf einem akzeptablen Niveau liegen sollte.
Das Wichtigste, was man verstehen muss, ist, dass eine Materialized View keine schlechte oder gute Lösung ist - sie gibt uns nur
die Möglichkeit, relativ schnell eine vereinfachte Trennung einzuführen, ohne den gesamten ereignisbasierten Mechanismus aufbauen zu müssen.
Aber wenn vollständige Trennung/Performance/Vendor Locking oder irgendetwas anderes uns hier zu stören beginnt, sollte es keine größeren Probleme beim Wechsel zu Projektionen geben.
Genau das macht Materialized View zu einer interessanten Lösung.
Die ideale Lösung
Existiert nicht...
Und das ist wahrscheinlich das Wichtigste, was ich in diesem Artikel vermitteln möchte.
Selbst wenn es uns gelingt, das Problem rein auf Technologie zu reduzieren, und selbst wenn wir durch ein Wunder alle zustimmen, dass Problem A mit Muster/Technik/Architektur B gelöst werden sollte...
Nichts davon könnte eine Rolle spielen, weil das Geschäft möglicherweise einfach kein größeres Refactoring genehmigt...
Und dies muss kein böser Wille oder Ignoranz sein - manchmal haben wir einfach nicht die Ressourcen.
Es ist schwer zu rechtfertigen, warum wir Zeit damit verbringen sollten, die Berechtigungsverwaltung in Module zu verschieben, wenn alles funktioniert und Gewinn generiert.
Genauso schwer wird es sein zu argumentieren, warum wir plötzlich, mit der Anforderung, ein Modul zu extrahieren, alle anderen reparieren müssen, indem wir asynchrone Kommunikation, Ereignisse, Wiederholungsmechanismen, Wiederherstellung usw. hinzufügen.
Es lohnt sich zu akzeptieren, dass die Welt nicht perfekt ist, nicht schwarz-weiß, und wir oft zwischen mehreren unvollkommenen Lösungen wählen müssen.
Was an einem Ort absolut falsch erscheinen mag, könnte in einem anderen Kontext akzeptabel sein, oder sogar wünschenswert.
Hilfe
Wenn Sie mit ähnlichen Problemen in Ihrem Projekt zu kämpfen haben und sich nicht ganz sicher sind, wie Sie diese lösen sollen,
kontaktieren Sie mich, und gemeinsam finden wir eine Lösung, die perfekt auf Ihre Bedürfnisse zugeschnitten ist.
Ich ermutige Sie auch, Discord - Flow PHP zu besuchen, wo wir direkt sprechen können.
