
I Lati Oscuri della Modularizzazione
Introduzione
Di recente mi sono imbattuto in un problema piuttosto interessante che mi ha fatto riflettere sugli aspetti meno glamour della modularizzazione - sai, quelle cose di cui di solito non si parla alle conferenze o ai workshop.
Cominciamo dalle basi. Cos'è esattamente la modularizzazione? In parole semplici, è dividere un sistema in parti indipendenti (moduli), dove ciascuna ha:
- Una responsabilità chiaramente definita
- Comunicazione tramite protocolli definiti
- La capacità di essere sviluppata indipendentemente dagli altri moduli
In breve, è un cenno al principio divide et impera. Invece di lottare con un problema enorme, complicato e intricato, lo dividiamo in problemi più piccoli che sono molto più facili da risolvere.
Molte persone sentono "modularizzazione" e pensano immediatamente "microservizi". Quindi, prima di andare avanti, chiariamo una cosa. I microservizi sono solo un modo per implementare la modularizzazione, proprio come un monolite modulare.
Lo Stato Attuale
Immagina un sistema composto da tre moduli.
Nota: Il diagramma qui sotto è un modello molto semplificato - il suo unico scopo è illustrare il problema.
- Modulo
IAM(Identity and Access) - utenti / gruppi / permessi Modulo A- gestione delle risorseModulo B- gestione di altre risorse
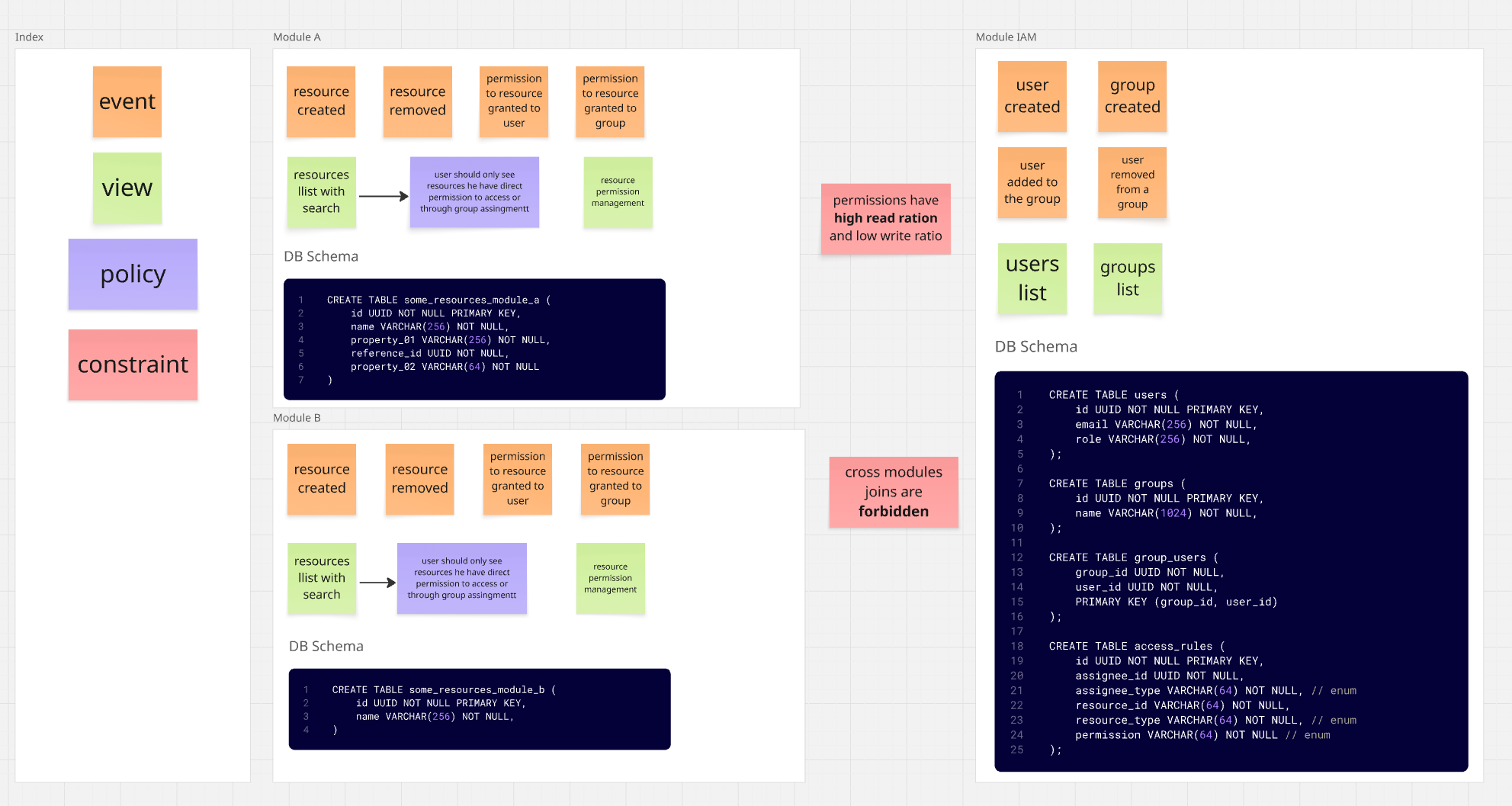
Il sistema di permessi qui è un po' complesso. Si basa principalmente su ACL (Access Control List),
il che significa concedere permessi alle risorse direttamente agli utenti o ai gruppi.
Inoltre, c'è anche del RBAC (Role Based Access Control), dove gli utenti con
ruoli specifici hanno permessi definiti per parti specifiche del sistema.
Abbiamo anche parzialmente ABAC (Attribute Based Access Control), dove i permessi derivano dagli attributi dell'utente,
in questo caso, l'appartenenza al gruppo.
Ti suona familiare? Non è un caso così unico come potresti pensare. Ma comunque, veniamo al punto.
Il Problema
Come puoi vedere nel diagramma, il sistema di permessi è definito nel modulo IAM - è lì che memorizziamo
informazioni su:
- Utenti e i loro ruoli
- Gruppi a cui gli utenti appartengono
- Permessi per risorse specifiche
I moduli A e B, nel frattempo, sono responsabili della gestione delle proprie risorse ma devono verificare che un dato utente abbia accesso a una risorsa specifica.
Quindi lo schema di dipendenza dei moduli è il seguente: I moduli A e B conoscono l'esistenza del modulo IAM (dipendono da esso), ma il modulo IAM stesso non ha idea che i moduli A e B esistano.
Il problema che il team ha incontrato era questo: "Come creiamo una lista paginata di risorse in un dato modulo basata sui permessi utente?"
Inoltre, la lista delle risorse deve consentire:
- Filtraggio basato sulle caratteristiche della risorsa
- Ordinamento basato sulle caratteristiche della risorsa
- Restituzione di una sola pagina selezionata
Questi requisiti rendono l'implementazione significativamente più difficile. Se non avessimo filtraggio/paginazione, potremmo semplicemente
interrogare direttamente il modulo IAM con una richiesta di restituire risorse per un dato utente.
Le caratteristiche delle risorse sono tutti i loro parametri e attributi che hanno senso e significato principalmente all'interno del loro
contesto. Esempi di caratteristiche delle risorse potrebbero essere il loro nome o la data di creazione. Questi sono parametri per i quali
l'utente dovrebbe poter ordinare o filtrare, ma che non esistono nel modulo IAM.
Ma senza caratteristiche delle risorse per cui possiamo filtrare/ordinare, il modulo IAM può al massimo restituire tutte le risorse,
e dovremmo fare il filtraggio dal lato del modulo. Non è esattamente una soluzione scalabile.
Non sapendo come uscire da questa situazione, il team ha deciso (consapevolmente o meno) di infrangere le regole della modularizzazione e accoppiare i moduli a livello di database.
Poiché il sistema è distribuito come monolite modulare e ogni modulo ha accesso allo stesso database (ogni modulo ha le proprie tabelle con un prefisso appropriato),
teoricamente nulla impedisce di costruire una query SQL che restituisce una lista di risorse per un modulo specifico
e unirla alle tabelle dei permessi del modulo IAM per filtrare le risorse a cui l'utente non ha accesso.
Veloce, semplice e funziona anche.
Questo potrebbe probabilmente coesistere pacificamente, tranne che c'è un nuovo requisito: dobbiamo estrarre uno dei moduli dal monolite...
Ed è qui che le cose si complicano. Come si estrae il Modulo A come servizio indipendente quando è strettamente accoppiato a livello di
database con il modulo IAM? Se rimuoviamo il join alle tabelle IAM, il controllo degli accessi
smetterà di funzionare.
Di seguito, presenterò tecniche che ci permetteranno di estrarre questo modulo dal monolite senza perdere funzionalità, infrangere le regole di modularizzazione o cambiare le dipendenze tra i moduli.
Quando si progetta un monolite modulare, vale la pena provare un approccio leggermente diverso. Invece di aggiungere prefissi alle tabelle, puoi creare database/schemi separati per ogni modulo all'interno di un singolo server di database, il che rende molto più difficile creare un accoppiamento accidentale a livello di query SQL.
Separazione delle Responsabilità
E se non fosse il modulo IAM ad essere responsabile dei permessi concessi alle risorse
che esistono solo in un modulo specifico?
Un possibile approccio (probabilmente il migliore per molti) è la separazione delle responsabilità, il che significa che IAM
gestisce l'autorizzazione, gli utenti, i loro ruoli e i gruppi a cui sono assegnati.
I moduli stessi gestiscono le regole dei permessi per le risorse. In pratica, questo significa spostare le tabelle access_rules
al Modulo A e al Modulo B.
Il risultato sarebbe un'architettura simile a quella qui sotto:
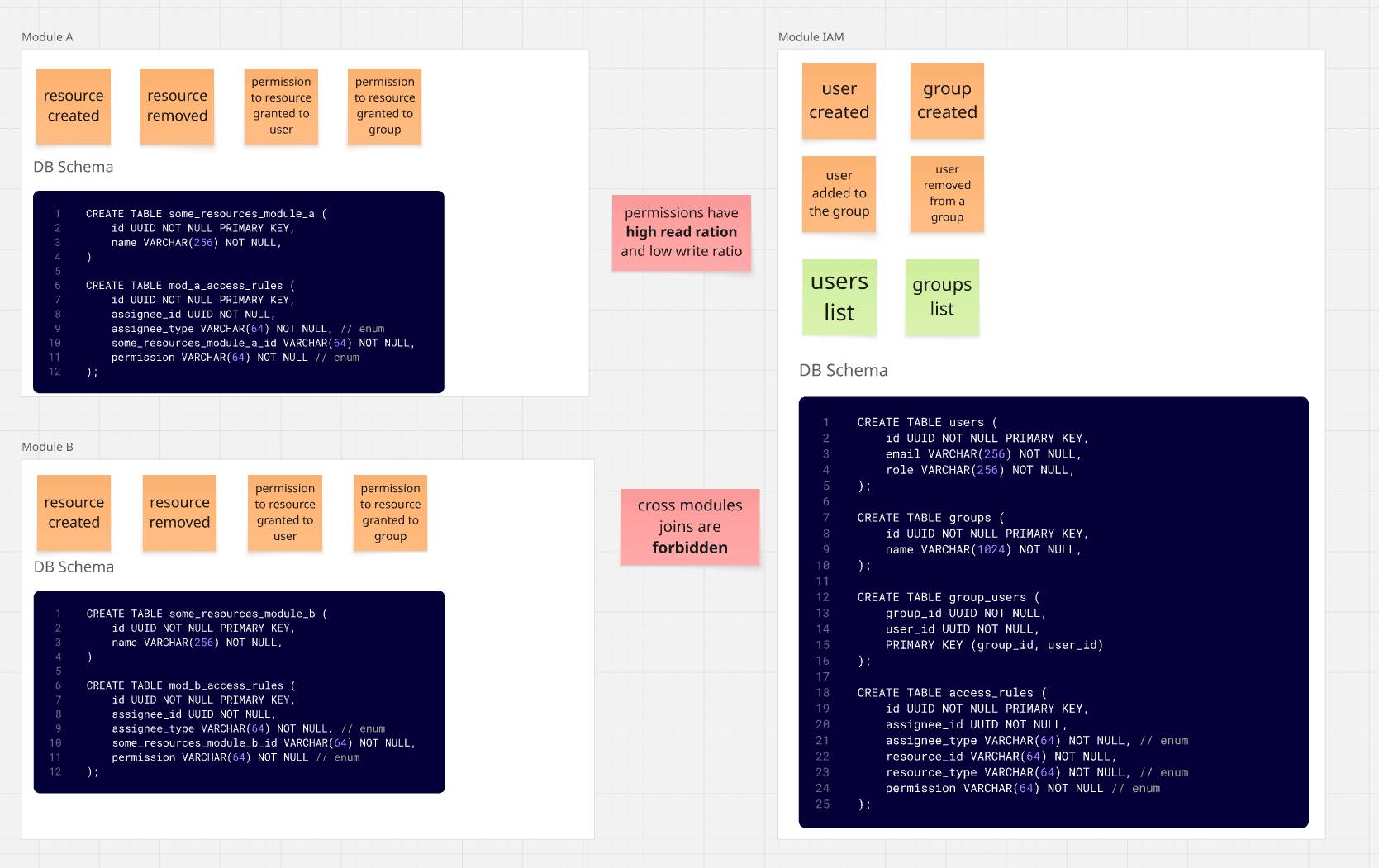
Nessuno dei moduli ha bisogno di fare viaggi a IAM per ottenere una lista di risorse disponibili
per un utente selezionato.
Abbiamo una certa duplicazione - essenzialmente dobbiamo ripetere la logica dei permessi per ogni modulo esistente e integrarla nei meccanismi del modulo esistenti.
Nota: Qui potresti essere tentato di creare un componente. A meno che tu non abbia persone nei tuoi team con esperienza nella costruzione di librerie/componenti, è meglio iniziare con la duplicazione. A lungo termine, la duplicazione fa molto meno male dell'astrazione sbagliata.
Ma è sufficiente?
Non del tutto. Se guardiamo la tabella dei permessi, noteremo che i permessi possono essere concessi direttamente a un utente o a un gruppo a cui l'utente appartiene.
Questo significa che nel Modulo A, concediamo permessi a una risorsa per il gruppo Gruppo 01, che include
l'Utente 01 e l'Utente 02.
Grazie a questo, entrambi gli utenti hanno accesso alla risorsa.
Ma cosa succede se rimuoviamo un utente dal gruppo selezionato?
Possiamo affrontare questo in due modi:
- Durante ogni verifica di accesso, interroghiamo il modulo
IAMper la lista dei gruppi dell'utente - Accettiamo la
consistenza eventualee manteniamo i gruppi utente nella sessione, aggiornandola ogni pochi/diversi minuti
La prima soluzione è la più semplice da implementare, non viola i confini di responsabilità dei moduli, ma potrebbe diventare rapidamente un collo di bottiglia.
Naturalmente, questo non accadrà immediatamente. Inoltre, a causa della natura dei dati (più letture che scritture), possiamo anche scaricare il database attraverso appropriati meccanismi di caching.
Per la soluzione numero due, dobbiamo assicurarci che sia anche una soluzione accettabile dal punto di vista del business.
Proiezione
Un altro approccio per risolvere il problema è mantenere la struttura dei permessi nel modulo IAM, ma
introdurre meccanismi che permettano al Modulo A e al Modulo B di sincronizzare
la tabella dei permessi con una proiezione locale.
Questa proiezione non è altro che una forma semplificata della tabella access_rules replicata in un modulo specifico.
Di conseguenza, otteniamo ancora una certa duplicazione, ma il Modulo A e il Modulo B
non si concentrano sulla gestione dei permessi - quella responsabilità è ancora delegata al modulo IAM.
La loro responsabilità si riduce alla sincronizzazione dei permessi con il modulo dei permessi.
Ma come e quando eseguiamo questa sincronizzazione? Ogni volta che concediamo permessi a una risorsa.
Il Modulo A, quando concede permessi a un utente o gruppo per una risorsa, prima
comunica con il modulo IAM.
Facciamo lo stesso quando revochiamo l'accesso a una risorsa. Prima rimuoviamo la voce nel modulo IAM, poi
rimuoviamo la voce nella proiezione locale.
Ma cosa succede se rimuoviamo un utente da un gruppo selezionato?
Qui torniamo essenzialmente allo stesso problema che avevamo nell'approccio precedente. Possiamo
recuperare la lista dei gruppi dell'utente dal modulo IAM ogni volta, o accettare la consistenza eventuale.
La differenza tra separazione e proiezione è molto piccola. Ma con le proiezioni, possiamo andare oltre.
Eventi
Il modulo IAM può anche propagare eventi relativi a:
- Aggiunta di un utente ai gruppi
- Rimozione di un utente da un gruppo
- Eliminazione di un gruppo
Per mantenere la corretta struttura di dipendenza, questi eventi non possono essere pubblicati "a un destinatario specifico".
Dobbiamo applicare un approccio Pub/Sub qui, dove IAM pubblica eventi su un
Topic specifico, a cui i moduli interessati possono iscriversi.
Grazie a questo, entrambi i moduli riceveranno una copia dello stesso evento, che potranno gestire indipendentemente.
Quando costruiamo una proiezione, possiamo anche semplificare significativamente la sua struttura scomponendo i gruppi in liste di utenti.
Se un gruppo riceve il permesso di accesso a una risorsa, invece di memorizzare
una voce nella proiezione che rappresenta il gruppo, possiamo creare una voce per ogni utente del gruppo.
Grazie a questo, durante la verifica dell'accesso, non abbiamo affatto bisogno di chiedere al modulo IAM. Dobbiamo solo
rispondere appropriatamente agli eventi propagati dal modulo IAM:
- Aggiunta di un utente a un gruppo
- Rimozione di un utente da un gruppo
- Eliminazione di un gruppo
Fondamentalmente, solo questi eventi ci interessano. L'aggiunta di un gruppo o utente in realtà non influisce su nulla, quindi possiamo tranquillamente ignorarli/filtrarli.
Affidabilità degli Eventi
Naturalmente, un approccio basato sugli eventi comporta certi rischi. Uno di questi è, ad esempio, l'ordine degli eventi disturbato.
Ad esempio, riceviamo prima un evento "utente rimosso dal gruppo", e solo dopo l'evento "utente aggiunto", quando
in realtà questi eventi si sono verificati nell'ordine opposto.
Sì, questo può essere un problema, specialmente quando il messaggio che contiene l'evento include anche tutti i dettagli di quell'evento.
Ma possiamo affrontare questo decidendo di usare eventi anemici - cioè eventi che essenzialmente contengono solo identificatori delle risorse che riguardano, e per tutto il resto devi andare al modulo sorgente.
Confrontiamo entrambi gli approcci usando l'evento UserRemovedFromGroup come esempio:
Evento Ricco (Rich Event)
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"userName": "jan.kowalski",
"userEmail": "[email protected]",
"groupId": 456,
"groupName": "Administrators",
"groupPermissions": ["read", "write", "delete"],
"removedBy": {
"userId": 789,
"userName": "admin"
}
}
}
Evento Anemico (Anemic Event)
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"groupId": 456
}
}
La differenza è fondamentale. Con un evento ricco, tutte le informazioni sull'utente, il gruppo e i permessi sono contenute nell'evento. Se l'ordine degli eventi viene disturbato, la nostra proiezione può finire in uno stato inconsistente.
Un evento anemico, d'altra parte, contiene solo identificatori. Dopo aver ricevuto un tale evento, il consumatore deve
fare una query aggiuntiva al modulo IAM per ottenere lo stato attuale. Grazie a questo, indipendentemente dall'ordine
in cui vengono ricevuti gli eventi, otterremo sempre la versione più aggiornata dei dati.
Scenario Problematico per Eventi Ricchi
Immaginiamo la seguente sequenza di eventi nel modulo IAM:
10:00:00- Utente aggiunto al gruppo "Administrators"10:00:05- Utente rimosso dal gruppo "Administrators"
Il consumatore nel Modulo A riceve gli eventi in ordine inverso:
- Riceve
UserRemovedFromGroup(con dati da 10:00:05) - Riceve
UserAddedToGroup(con dati da 10:00:00)
Con eventi ricchi, la proiezione nel Modulo A mostra che l'utente appartiene al gruppo (perché l'ultimo evento ricevuto era "aggiunta"), anche se in realtà è già stato rimosso da esso.
Con eventi anemici, indipendentemente dall'ordine di ricezione, il Modulo A eseguirà una query a IAM e otterrà lo stato attuale - l'utente non appartiene al gruppo.
Gli eventi anemici riducono il rischio di inconsistenza, ma non lo eliminano completamente. C'è ancora la possibilità che tra la ricezione dell'evento e la query a IAM, lo stato cambi. Quindi potresti considerare di aggiungere un numero di versione o timestamp agli eventi e verificarli durante l'aggiornamento della proiezione. Anche se i meccanismi di protezione dipenderanno in gran parte dal traffico e dalla frequenza dei cambiamenti.
Ecco come appare:
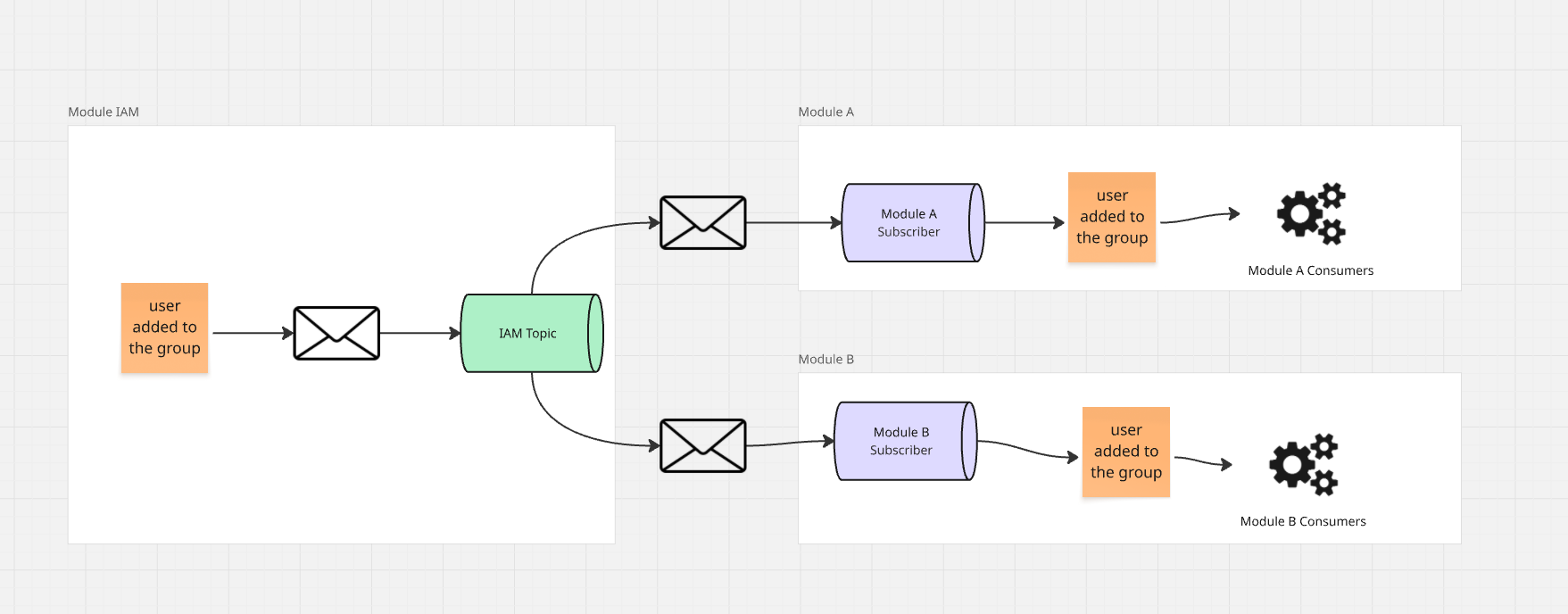
Quando il consumatore del Modulo A riceve informazioni, il suo compito è andare al modulo IAM e chiedergli
tutte le regole per un gruppo specifico. Il modulo IAM può restituire i record dalla tabella dei permessi riguardanti
un gruppo specifico, e poi, se esistono regole, possiamo chiedere gli utenti di quel gruppo e nella
proiezione locale del modulo costruire una proiezione dei permessi per loro.
Possiamo anche facilitarci un po' la vita e aggiungere al protocollo di comunicazione con il modulo IAM la capacità di
recuperare una struttura piatta di permessi, che restituisce non il gruppo ma una lista di utenti del gruppo con permessi per
una risorsa specifica.
Nota: Per fornire garanzie aggiuntive di consegna degli eventi, considera di implementare il pattern Outbox.
Aspetta, ma il modulo IAM non diventerà di nuovo un collo di bottiglia?
Non esattamente. Ciò che conta qui non è solo la query stessa, ma piuttosto la sua frequenza. Il controllo dei permessi è uno di quei processi dove chiediamo dei permessi molto più spesso di quanto li modifichiamo.
Naturalmente, non credere semplicemente sulla parola - se hai un sistema esistente con controllo dei permessi, vale la pena semplicemente misurarlo.
Ma tornando al punto, quando si usano eventi anemici, non dobbiamo preoccuparci tanto dell' ordine in cui vengono ricevuti. Non ci basiamo sul contenuto dell'evento ma solo sull'identificatore della risorsa che riguarda, il che rende la costruzione di proiezioni molto più facile.
Ma questo ha il suo costo - ora dopo ogni evento dobbiamo andare alla fonte per determinare lo stato effettivo.
Quindi vale la pena analizzare questo approccio dal punto di vista delle prestazioni.
Ci sono comunque più tecniche per gestire gli eventi. Puoi trovarne una su https://event-driven.io/.
Duplicazione
In entrambi gli approcci, tuttavia, si presenta il problema della duplicazione. Anche se in questo caso, "problema" è probabilmente la parola sbagliata. È semplicemente un costo della modularizzazione di cui semplicemente non si parla.
Indipendentemente dal fatto che decidiamo per la separazione delle responsabilità o la costruzione di proiezioni, i Moduli A e B duplicheranno la logica relativa ai permessi in misura maggiore o minore.
Quindi indipendentemente dal nostro modello di distribuzione (monolite / microservizi) e indipendentemente da come separiamo i confini dei moduli e le loro responsabilità, dobbiamo semplicemente prepararci a questo costo.
Il mio consiglio qui è sempre di iniziare con la duplicazione. Anche se le nostre implementazioni non differiscono affatto tra i moduli.
È molto più facile estrarre parti comuni da soluzioni esistenti che progettare parti comuni per soluzioni che non esistono ancora.
Cosa è Meglio?
Non c'è una risposta chiara a questa domanda. Ma possiamo provare ad analizzare la nostra situazione e scegliere una soluzione che ci permetterà di estrarre uno dei moduli e sbarazzarci dell'accoppiamento a livello di database.
Per il modulo che deve essere estratto, suggerirei (se possibile) la separazione delle responsabilità e lo spostamento della gestione dei permessi delle risorse a quel modulo.
Dal momento che dobbiamo comunque fare del lavoro, dal momento che dobbiamo comunque separare fisicamente questo modulo dal nostro monolite,
potremmo anche andare oltre e ridurre la sua dipendenza da
IAM ancora di più a un costo relativamente basso.
Ma un'operazione del genere ha senso per i moduli esistenti?
Per i moduli che non devono essere estratti e continueranno a vivere all'interno del monolite modulare, suggerirei un approccio basato sulla proiezione, ma non necessariamente con eventi.
Proiezioni Senza Eventi
Questa è una tecnica che non funzionerà in un approccio a microservizi, ma può aiutare come soluzione temporanea. Non solo aiutare, ma anche indicare la strada da seguire. Puoi implementarla a basso costo, ottenendo essenzialmente la stessa cosa di un approccio basato sugli eventi.
Guardiamolo da un'angolazione diversa. Pub/Sub è essenzialmente un meccanismo che ci permette una certa forma di replica. Grazie agli eventi, sappiamo che qualcosa è successo in un certo momento in un certo modulo.
E se invece di pubblicare un evento su un Topic, usassimo Viste Materializzate?
Sì, lo so - molte persone stanno probabilmente vedendo bandiere rosse adesso. Voglio dire, viste materializzate? Logica lato database invece che nel codice?
Beh, non è una soluzione ideale. Certo, ci liberiamo dell'accoppiamento a livello SQL, ma in cambio otteniamo un accoppiamento diverso - questa volta a livello di database.
Ma se affrontiamo questo pragmaticamente, stiamo essenzialmente solo scambiando il meccanismo di trasporto. Invece di costruire pub/sub, implementare il pattern Outbox, gestire errori di comunicazione di rete, tentativi, ecc., possiamo semplicemente lasciare che il database gestisca la replica dei dati.
Se per qualche motivo questo smette di funzionare per noi - come quando l'aggiornamento della vista materializzata diventa troppo costoso e inizia a caricare inutilmente il nostro database - nulla ci impedirà di passare alle proiezioni.
Ma prima di arrivare a quel punto, possiamo anche provare a mettere il processo di aggiornamento stesso in una coda nel modulo IAM
ed eseguirlo in modo asincrono. Otterremo un leggero ritardo, anche se in questo caso dovrebbe essere a un livello accettabile.
La cosa fondamentale da capire è che una Vista Materializzata non è una soluzione né cattiva né buona - ci dà solo
la capacità di introdurre una separazione semplificata relativamente rapidamente senza dover costruire l'intero meccanismo basato sugli eventi.
Ma quando la separazione completa/prestazioni/vendor locking o qualsiasi altra cosa inizia a darci fastidio qui, non dovrebbero esserci problemi importanti nel passare alle proiezioni.
Questo è esattamente ciò che rende Vista Materializzata una soluzione interessante.
La Soluzione Ideale
Non esiste...
E questo è probabilmente la cosa più importante che voglio trasmettere in questo articolo.
Anche se riusciamo a ridurre il problema puramente alla tecnologia, e anche se per qualche miracolo siamo tutti d'accordo che il problema A dovrebbe essere risolto con pattern/tecnica/architettura B...
Niente di tutto ciò potrebbe avere importanza perché il business potrebbe semplicemente non approvare un refactoring importante...
E questo non deve essere cattiva fede o ignoranza - a volte semplicemente non abbiamo le risorse.
È difficile giustificare perché dovremmo passare del tempo a spostare la gestione dei permessi ai moduli quando tutto funziona e genera profitti.
Altrettanto difficile quanto sarà argomentare perché improvvisamente, con un requisito di estrarre un modulo, dobbiamo correggere tutti gli altri, aggiungendo comunicazione asincrona, eventi, meccanismi di retry, recovery, ecc.
Vale la pena accettare che il mondo non è perfetto, non è bianco e nero, e spesso dovremo scegliere tra diverse soluzioni imperfette.
Ciò che potrebbe sembrare assolutamente scorretto in un posto potrebbe essere accettabile in un altro contesto, o addirittura desiderabile.
Aiuto
Se stai affrontando problemi simili nel tuo progetto e non sei del tutto sicuro di come risolverli,
contattami, e insieme troveremo una soluzione perfettamente adattata alle tue esigenze.
Ti incoraggio anche a visitare Discord - Flow PHP, dove possiamo parlare direttamente.
