
Los Lados Oscuros de la Modularización
Introducción
Hace poco me topé con un problema bastante interesante que me hizo reflexionar sobre los aspectos menos glamorosos de la modularización - ya sabes, esas cosas de las que normalmente no hablamos en conferencias o talleres.
Empecemos por lo básico. ¿Qué es exactamente la modularización? En pocas palabras, es dividir un sistema en partes independientes (módulos), donde cada uno tiene:
- Una responsabilidad claramente definida
- Comunicación a través de protocolos definidos
- La capacidad de desarrollarse independientemente de otros módulos
En resumen, es un guiño al principio de divide y vencerás. En lugar de luchar con un problema enorme, complicado y enredado, lo dividimos en problemas más pequeños que son mucho más fáciles de resolver.
Mucha gente escucha "modularización" y piensa inmediatamente en "microservicios". Así que antes de continuar, aclaremos algo. Los microservicios son solo una forma de implementar la modularización, al igual que un monolito modular.
El Estado Actual
Imagina un sistema compuesto por tres módulos.
Nota: El diagrama a continuación es un modelo muy simplificado - su único propósito es ilustrar el problema.
- Módulo
IAM(Identity and Access) - usuarios / grupos / permisos Módulo A- gestión de recursosMódulo B- gestión de otros recursos
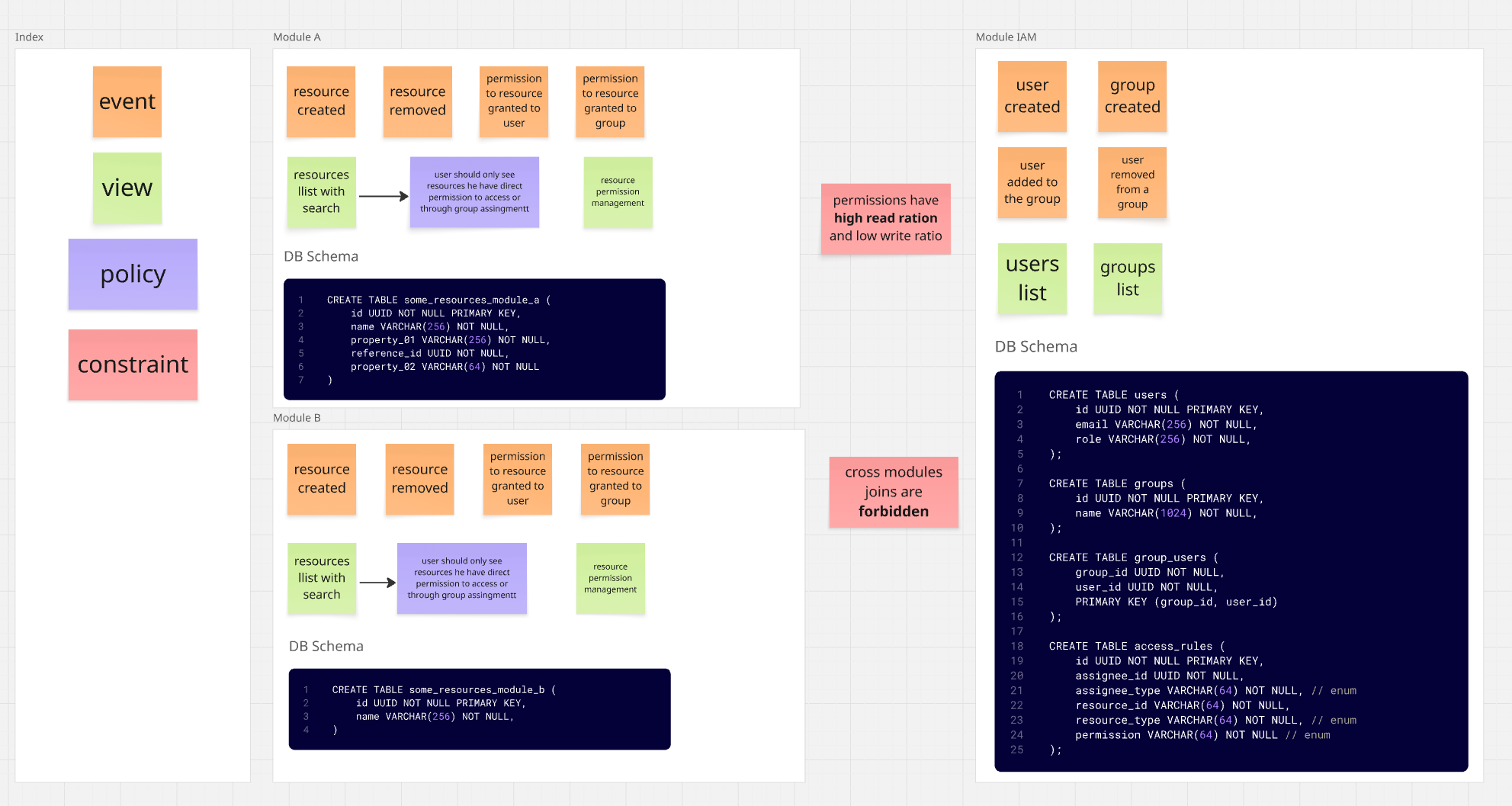
El sistema de permisos aquí es un poco complejo. Se basa principalmente en ACL (Access Control List),
lo que significa otorgar permisos a recursos directamente a usuarios o grupos.
Además, también hay algo de RBAC (Role Based Access Control), donde los usuarios con
roles específicos tienen permisos definidos para partes específicas del sistema.
También tenemos parcialmente ABAC (Attribute Based Access Control), donde los permisos se derivan de atributos del usuario,
en este caso, la pertenencia a grupos.
¿Te suena familiar? Este no es un caso tan único como podrías pensar. Pero en fin, vayamos al grano.
El Problema
Como puedes ver en el diagrama, el sistema de permisos está definido en el módulo IAM - ahí es donde almacenamos
información sobre:
- Usuarios y sus roles
- Grupos a los que pertenecen los usuarios
- Permisos para recursos específicos
Los módulos A y B, mientras tanto, son responsables de gestionar sus propios recursos, pero necesitan verificar que un usuario determinado tenga acceso a un recurso específico.
Así que el esquema de dependencias de módulos se ve así: Los módulos A y B saben de la existencia del módulo IAM (dependen de él), pero el módulo IAM en sí no tiene idea de que existen los módulos A y B.
El problema con el que se encontró el equipo fue este: "¿Cómo creamos una lista paginada de recursos en un módulo determinado basada en permisos de usuario?"
Además, la lista de recursos necesita permitir:
- Filtrado basado en características del recurso
- Ordenación basada en características del recurso
- Devolver solo una página seleccionada
Estos requisitos hacen que la implementación sea significativamente más difícil. Si no tuviéramos filtrado/paginación, podríamos simplemente
consultar directamente al módulo IAM con una solicitud para devolver recursos para un usuario determinado.
Las características del recurso son todos sus parámetros y atributos que tienen sentido y significado principalmente dentro de su
propio contexto. Ejemplos de características del recurso podrían ser su nombre o fecha de creación. Estos son parámetros por los que
el usuario debería poder ordenar o filtrar, pero que no existen en el módulo IAM.
Pero sin características del recurso por las que podamos filtrar/ordenar, el módulo IAM puede, en el mejor de los casos, devolver todos los recursos,
y tendríamos que hacer el filtrado en el lado del módulo. No es exactamente una solución escalable.
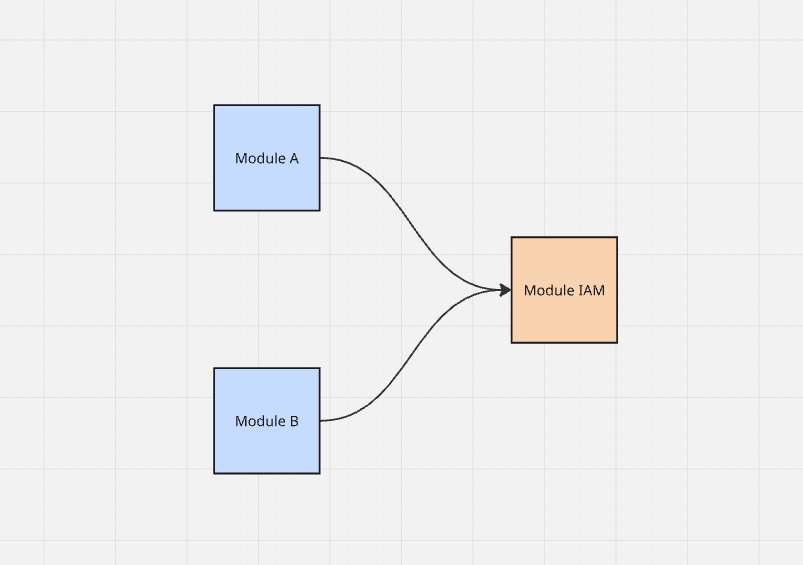
Sin saber cómo salir de esta situación, el equipo decidió (consciente o inconscientemente) romper las reglas de modularización y acoplar los módulos a nivel de base de datos.
Dado que el sistema está desplegado como un monolito modular y cada módulo tiene acceso a la misma base de datos (cada módulo tiene sus propias tablas con un prefijo apropiado),
teóricamente nada impide construir una consulta SQL que devuelva una lista de recursos para un módulo específico
y unirla con las tablas de permisos del módulo IAM para filtrar los recursos a los que el usuario no tiene acceso.
Rápido, simple y hasta funciona.
Esto probablemente podría coexistir pacíficamente, excepto por un nuevo requisito: necesitamos extraer uno de los módulos del monolito...
Y aquí es donde las cosas se complican. ¿Cómo extraes el Módulo A como un servicio independiente cuando está estrechamente acoplado a nivel de
base de datos con el módulo IAM? Si eliminamos el join a las tablas de IAM, el control de acceso
dejará de funcionar.
A continuación, presentaré técnicas que nos permitirán extraer este módulo del monolito sin perder funcionalidad, romper las reglas de modularización o cambiar las dependencias entre módulos.
Al diseñar un monolito modular, vale la pena intentar un enfoque ligeramente diferente. En lugar de prefijar tablas, puedes crear bases de datos/esquemas separados para cada módulo dentro de un único servidor de base de datos, lo que hace mucho más difícil crear un acoplamiento accidental a nivel de consulta SQL.
División de Responsabilidades
¿Y si no fuera el módulo IAM el responsable de los permisos otorgados a recursos
que solo existen en un módulo específico?
Un enfoque posible (probablemente el mejor para muchos) es la separación de responsabilidades, lo que significa que IAM
maneja la autorización, usuarios, sus roles y los grupos a los que están asignados.
Los módulos mismos gestionan las reglas de permisos para recursos. En la práctica, esto significa mover las tablas access_rules
al Módulo A y al Módulo B.
El resultado sería una arquitectura similar a la siguiente:
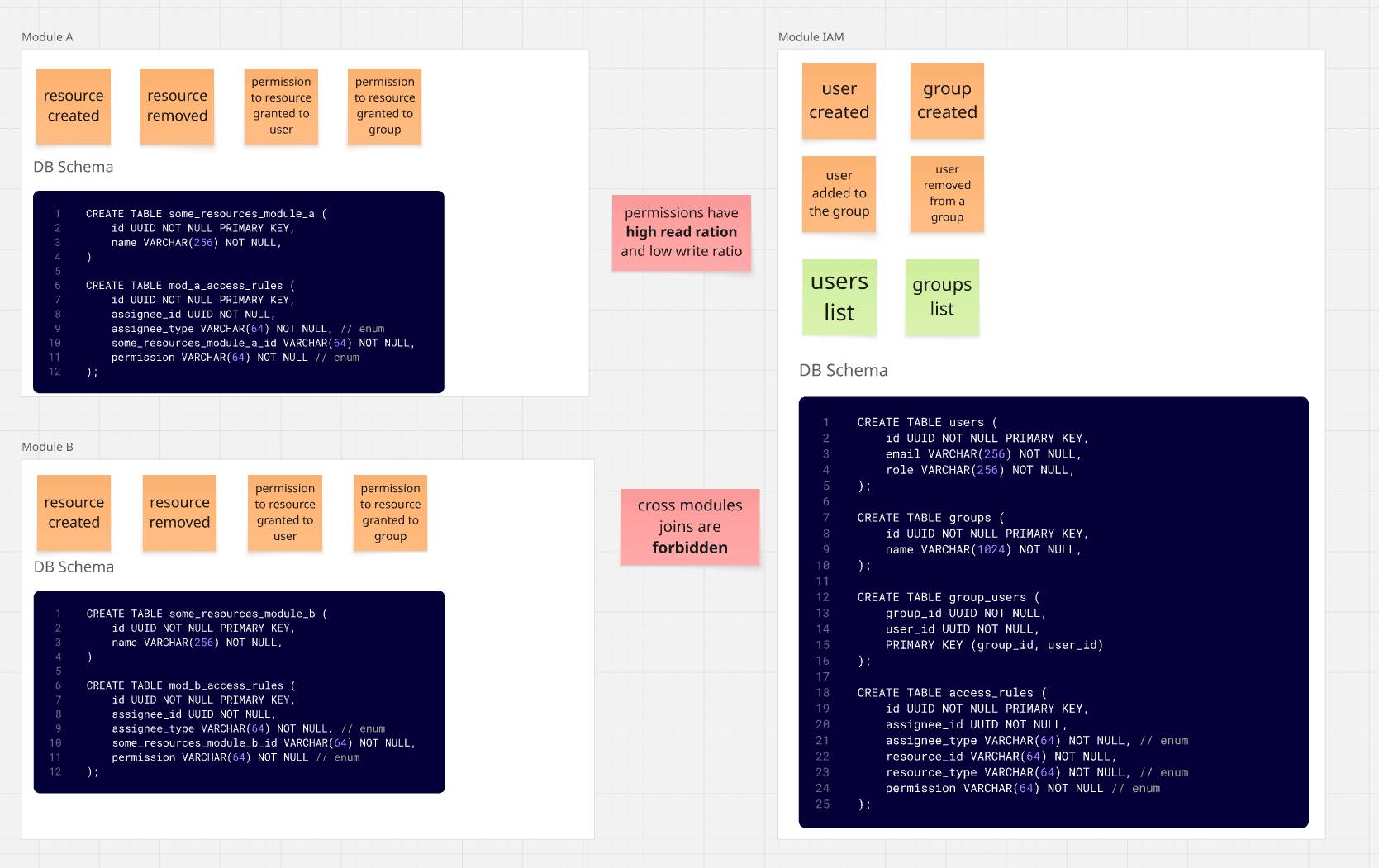
Ninguno de los módulos necesita hacer viajes a IAM para obtener una lista de recursos disponibles
para un usuario seleccionado.
Sí tenemos algo de duplicación - básicamente necesitamos repetir la lógica de permisos para cada módulo existente e integrarla en los mecanismos de módulo existentes.
Nota: Aquí podrías sentir la tentación de crear un componente. A menos que tengas personas en tus equipos con experiencia en la construcción de bibliotecas/componentes, es mejor comenzar con duplicación. A largo plazo, la duplicación duele mucho menos que la abstracción incorrecta.
¿Pero es eso suficiente?
No del todo. Si miramos la tabla de permisos, notaremos que los permisos pueden otorgarse directamente a un usuario o a un grupo al que pertenece el usuario.
Esto significa que en el Módulo A, otorgamos permisos a un recurso para el grupo Grupo 01, que incluye
al Usuario 01 y al Usuario 02.
Gracias a esto, ambos usuarios tienen acceso al recurso.
¿Pero qué pasa si eliminamos un usuario del grupo seleccionado?
Podemos abordar esto de dos maneras:
- Durante cada verificación de acceso, consultamos al módulo
IAMpor la lista de grupos del usuario - Aceptamos la
consistencia eventualy mantenemos los grupos de usuario en la sesión, refrescándola cada pocos/varios minutos
La primera solución es la más simple de implementar, no viola los límites de responsabilidad del módulo, pero podría convertirse en un cuello de botella bastante rápido.
Por supuesto, esto no sucederá de inmediato. Además, debido a la naturaleza de los datos (más lecturas que escrituras), también podemos descargar la base de datos a través de mecanismos de caché apropiados.
Para la solución número dos, necesitamos asegurarnos de que sea siquiera una solución aceptable desde la perspectiva del negocio.
Proyección
Otro enfoque para resolver el problema es mantener la estructura de permisos en el módulo IAM, pero
introducir mecanismos que permitan al Módulo A y al Módulo B sincronizar
la tabla de permisos con una proyección local.
Esta proyección no es más que una forma simplificada de la tabla access_rules replicada en un módulo específico.
Como resultado, todavía obtenemos algo de duplicación, pero el Módulo A y el Módulo B
no se centran en gestionar permisos - esa responsabilidad sigue delegada al módulo IAM.
Su responsabilidad se reduce a sincronizar permisos con el módulo de permisos.
Pero ¿cómo y cuándo realizamos esta sincronización? Cada vez que otorgamos permisos a un recurso.
El Módulo A, al otorgar permisos a un usuario o grupo para algún recurso, primero
se comunica con el módulo IAM.
Hacemos lo mismo al revocar el acceso a un recurso. Primero eliminamos la entrada en el módulo IAM, luego
eliminamos la entrada en la proyección local.
¿Pero qué pasa si eliminamos un usuario de un grupo seleccionado?
Aquí básicamente volvemos al mismo problema que teníamos en el enfoque anterior. Podemos
obtener la lista de grupos del usuario del módulo IAM cada vez, o aceptar la consistencia eventual.
La diferencia entre separación y proyección es muy pequeña. Pero con proyecciones, podemos ir un paso más allá.
Eventos
El módulo IAM también puede propagar eventos relacionados con:
- Agregar un usuario a grupos
- Eliminar un usuario de un grupo
- Eliminar un grupo
Para mantener la estructura de dependencia adecuada, estos eventos no pueden publicarse "a un destinatario específico".
Necesitamos aplicar un enfoque Pub/Sub aquí, donde IAM publica eventos a un
Topic específico, al que los módulos interesados pueden suscribirse.
Gracias a esto, ambos módulos recibirán una copia del mismo evento, que pueden manejar independientemente.
Al construir una proyección, también podemos simplificar significativamente su estructura dividiendo grupos en listas de usuarios.
Si un grupo recibe permiso de acceso a algún recurso, en lugar de almacenar
una entrada en la proyección que represente al grupo, podemos crear una entrada para cada usuario del grupo.
Gracias a esto, durante la verificación de acceso, no necesitamos preguntar al módulo IAM por nada en absoluto. Solo necesitamos
responder apropiadamente a los eventos propagados por el módulo IAM:
- Agregar un usuario a un grupo
- Eliminar un usuario de un grupo
- Eliminar un grupo
Básicamente, solo estos eventos nos importan. Agregar un grupo o usuario en realidad no afecta nada, así que podemos ignorarlos/filtrarlos de forma segura.
Fiabilidad de Eventos
Por supuesto, un enfoque basado en eventos conlleva ciertos riesgos. Uno de ellos es, por ejemplo, el orden de eventos interrumpido.
Por ejemplo, primero recibimos un evento de "usuario eliminado del grupo", y solo después el evento de "usuario agregado", cuando
en realidad estos eventos ocurrieron en el orden opuesto.
Sí, esto puede ser un problema, especialmente cuando el mensaje que contiene el evento también incluye todos los detalles de ese evento.
Pero podemos lidiar con esto decidiendo usar eventos anémicos - es decir, eventos que básicamente solo contienen identificadores de los recursos a los que conciernen, y para todo lo demás necesitas ir al módulo fuente.
Comparemos ambos enfoques usando el evento UserRemovedFromGroup como ejemplo:
Evento Rico (Rich Event)
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"userName": "jan.kowalski",
"userEmail": "[email protected]",
"groupId": 456,
"groupName": "Administrators",
"groupPermissions": ["read", "write", "delete"],
"removedBy": {
"userId": 789,
"userName": "admin"
}
}
}
Evento Anémico (Anemic Event)
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"groupId": 456
}
}
La diferencia es fundamental. Con un evento rico, toda la información sobre el usuario, el grupo y los permisos está contenida en el evento. Si el orden de los eventos se interrumpe, nuestra proyección puede terminar en un estado inconsistente.
Un evento anémico, por otro lado, solo contiene identificadores. Después de recibir tal evento, el consumidor debe
hacer una consulta adicional al módulo IAM para obtener el estado actual. Gracias a esto, independientemente del orden
en que se reciban los eventos, siempre obtendremos la versión más actualizada de los datos.
Escenario Problemático para Eventos Ricos
Imaginemos la siguiente secuencia de eventos en el módulo IAM:
10:00:00- Usuario agregado al grupo "Administrators"10:00:05- Usuario eliminado del grupo "Administrators"
El consumidor en el Módulo A recibe eventos en orden inverso:
- Recibe
UserRemovedFromGroup(con datos de 10:00:05) - Recibe
UserAddedToGroup(con datos de 10:00:00)
Con eventos ricos, la proyección en el Módulo A muestra que el usuario pertenece al grupo (porque el último evento recibido fue "adición"), aunque en realidad ya ha sido eliminado de él.
Con eventos anémicos, independientemente del orden recibido, el Módulo A ejecutará una consulta a IAM y obtendrá el estado actual - el usuario no pertenece al grupo.
Los eventos anémicos reducen el riesgo de inconsistencia, pero no lo eliminan por completo. Todavía existe la posibilidad de que entre recibir el evento y consultar a IAM, el estado cambie. Así que podrías considerar agregar un número de versión o marca de tiempo a los eventos y verificarlos al actualizar la proyección. Aunque los mecanismos de protección dependerán en gran medida del tráfico y la frecuencia de cambios.
Así es como se ve:
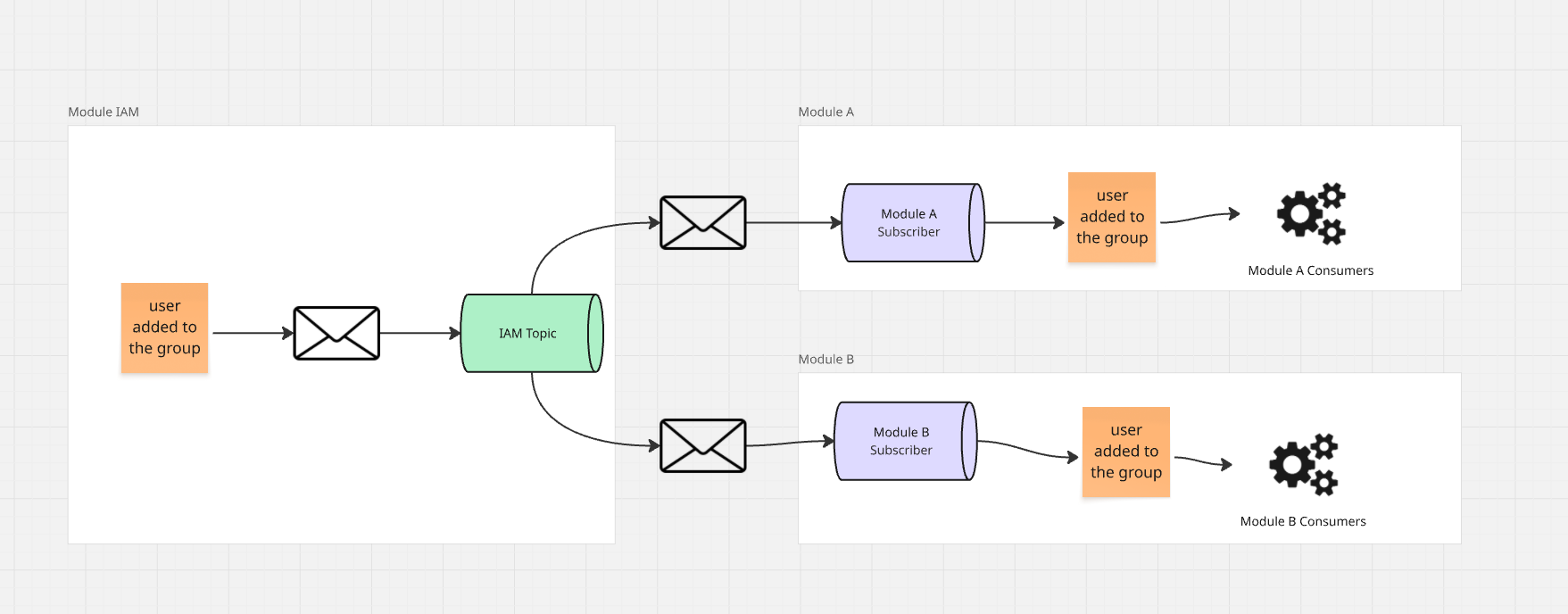
Cuando el consumidor del Módulo A recibe información, su trabajo es ir al módulo IAM y preguntarle
por todas las reglas para un grupo específico. El módulo IAM puede devolver registros de la tabla de permisos concernientes a
un grupo específico, y luego, si existen reglas, podemos preguntar por los usuarios de ese grupo y en
la proyección local del módulo construir una proyección de permisos para ellos.
También podemos facilitarnos un poco la vida y agregar al protocolo de comunicación con el módulo IAM la capacidad de
obtener una estructura plana de permisos, que devuelva no el grupo sino una lista de usuarios del grupo con permisos a
un recurso específico.
Nota: Para proporcionar garantías adicionales de entrega de eventos, considera implementar el patrón Outbox.
Espera, ¿pero no se convertirá el módulo IAM en un cuello de botella otra vez?
No del todo. Lo que importa aquí no es solo la consulta en sí, sino más bien su frecuencia. El control de permisos es uno de esos procesos donde preguntamos sobre permisos con mucha más frecuencia de lo que los cambiamos.
Por supuesto, no me creas solo a mí - si tienes un sistema existente con control de permisos, vale la pena simplemente medirlo.
Pero volviendo al punto, al usar eventos anémicos, no tenemos que preocuparnos tanto por el orden en que se reciben. No confiamos en el contenido del evento sino solo en el identificador del recurso que concierne, lo que hace que construir proyecciones sea mucho más fácil.
Pero esto tiene su costo - ahora después de cada evento necesitamos ir a la fuente para determinar el estado real.
Así que vale la pena analizar este enfoque desde una perspectiva de rendimiento.
Sin embargo, hay más técnicas para lidiar con eventos. Puedes encontrar una en https://event-driven.io/.
Duplicación
En ambos enfoques, sin embargo, surge el problema de la duplicación. Aunque en este caso, "problema" es probablemente la palabra equivocada. Es simplemente un costo de la modularización del que simplemente no se habla.
Independientemente de si decidimos la separación de responsabilidades o la construcción de proyecciones, los Módulos A y B duplicarán la lógica relacionada con permisos en mayor o menor medida.
Así que independientemente de nuestro modelo de despliegue (monolito / microservicios) e independientemente de cómo separemos los límites de módulos y sus responsabilidades, simplemente necesitamos prepararnos para este costo.
Mi consejo aquí es siempre comenzar con duplicación. Incluso si nuestras implementaciones no difieren en absoluto entre módulos.
Es mucho más fácil extraer partes comunes de soluciones existentes que diseñar partes comunes para soluciones que aún no existen.
¿Qué es Mejor?
No hay una respuesta clara a esta pregunta. Pero podemos intentar analizar nuestra situación y elegir una solución que nos permita extraer uno de los módulos y deshacernos del acoplamiento a nivel de base de datos.
Para el módulo que necesita ser extraído, sugeriría (si es posible) la separación de responsabilidades y mover la gestión de permisos de recursos a ese módulo.
Ya que de todos modos tenemos que hacer algo de trabajo, ya que tenemos que separar físicamente este módulo de nuestro monolito,
también podríamos ir un paso más allá y reducir su dependencia de
IAM aún más a un costo relativamente bajo.
¿Pero tiene sentido tal operación para los módulos existentes?
Para los módulos que no necesitan ser extraídos y continuarán viviendo dentro del monolito modular, sugeriría un enfoque basado en proyección, pero no necesariamente con eventos.
Proyecciones Sin Eventos
Esta es una técnica que no funcionará en un enfoque de microservicios, pero puede ayudar como solución provisional. No solo ayudar, sino también señalar el camino a seguir. Puedes implementarla a bajo costo, obteniendo básicamente lo mismo que con un enfoque basado en eventos.
Mirémoslo desde un ángulo diferente. Pub/Sub es básicamente un mecanismo que nos permite una cierta forma de replicación. Gracias a los eventos, sabemos que algo sucedió en algún momento en algún módulo.
¿Qué tal si en lugar de publicar un evento a un Topic, usáramos Vistas Materializadas?
Sí, lo sé - mucha gente probablemente está viendo banderas rojas ahora mismo. Quiero decir, ¿vistas materializadas? ¿Lógica en el lado de la base de datos en lugar de en el código?
Bueno, no es una solución ideal. Claro, nos deshacemos del acoplamiento a nivel SQL, pero a cambio obtenemos un acoplamiento diferente - esta vez a nivel de base de datos.
Pero si abordamos esto pragmáticamente, básicamente solo estamos intercambiando el mecanismo de transporte. En lugar de construir pub/sub, implementar el patrón Outbox, manejar errores de comunicación de red, reintentos, etc., podemos simplemente dejar que la base de datos maneje la replicación de datos.
Si por alguna razón esto deja de funcionarnos - como cuando actualizar la vista materializada se vuelve demasiado costoso y comienza a cargar innecesariamente nuestra base de datos - nada nos impedirá cambiar a proyecciones.
Pero antes de llegar a ese punto, también podemos intentar poner el proceso de actualización mismo en una cola en el módulo IAM
y ejecutarlo de forma asíncrona. Obtendremos un ligero retraso, aunque en este caso debería estar en un nivel aceptable.
Lo clave es entender que una Vista Materializada no es una solución mala ni buena - solo nos da
la capacidad de introducir una separación simplificada relativamente rápido sin tener que construir todo el mecanismo basado en eventos.
Pero cuando la separación completa/rendimiento/bloqueo de proveedor o cualquier otra cosa comience a molestarnos aquí, no debería haber problemas mayores al cambiar a proyecciones.
Eso es exactamente lo que hace que Vista Materializada sea una solución interesante.
La Solución Ideal
No existe...
Y eso es probablemente lo más importante que quiero transmitir en este artículo.
Incluso si logramos reducir el problema puramente a tecnología, e incluso si por algún milagro todos estamos de acuerdo en que el problema A debe resolverse con patrón/técnica/arquitectura B...
Nada de eso podría importar porque el negocio simplemente podría no aprobar una refactorización importante...
Y esto no tiene que ser mala fe o ignorancia - a veces simplemente no tenemos los recursos.
Es difícil justificar por qué deberíamos pasar tiempo moviendo la gestión de permisos a módulos cuando todo funciona y genera ganancias.
Tan difícil como será argumentar por qué de repente, con un requisito de extraer un módulo, tenemos que arreglar todos los demás, agregando comunicación asíncrona, eventos, mecanismos de reintento, recuperación, etc.
Vale la pena aceptar que el mundo no es perfecto, no es blanco y negro, y a menudo tendremos que elegir entre varias soluciones imperfectas.
Lo que podría parecer absolutamente incorrecto en un lugar podría ser aceptable en otro contexto, o incluso deseable.
Ayuda
Si estás luchando con problemas similares en tu proyecto y no estás muy seguro de cómo resolverlos,
ponte en contacto conmigo, y juntos encontraremos una solución perfectamente adaptada a tus necesidades.
También te animo a visitar Discord - Flow PHP, donde podemos hablar directamente.
