
Les Côtés Sombres de la Modularisation
Introduction
Je suis récemment tombé sur un problème assez intéressant qui m'a fait réfléchir aux aspects moins glamour de la modularisation - vous savez, ces choses dont on ne parle généralement pas lors des conférences ou des ateliers.
Commençons par les bases. Qu'est-ce que la modularisation exactement ? En termes simples, c'est diviser un système en parties indépendantes (modules), où chacune possède :
- Une responsabilité clairement définie
- Une communication via des protocoles définis
- La capacité d'être développée indépendamment des autres modules
En bref, c'est un clin d'œil au principe diviser pour mieux régner. Plutôt que de lutter avec un problème énorme, compliqué et enchevêtré, nous le divisons en problèmes plus petits qui sont beaucoup plus faciles à résoudre.
Beaucoup de gens entendent "modularisation" et pensent immédiatement "microservices". Alors avant d'aller plus loin, clarifions une chose. Les microservices ne sont qu'une façon d'implémenter la modularisation, tout comme un monolithe modulaire.
L'État Actuel
Imaginez un système composé de trois modules.
Note : Le diagramme ci-dessous est un modèle très simplifié - son seul but est d'illustrer le problème.
- Module
IAM(Identity and Access) - utilisateurs / groupes / permissions Module A- gestion des ressourcesModule B- gestion d'autres ressources
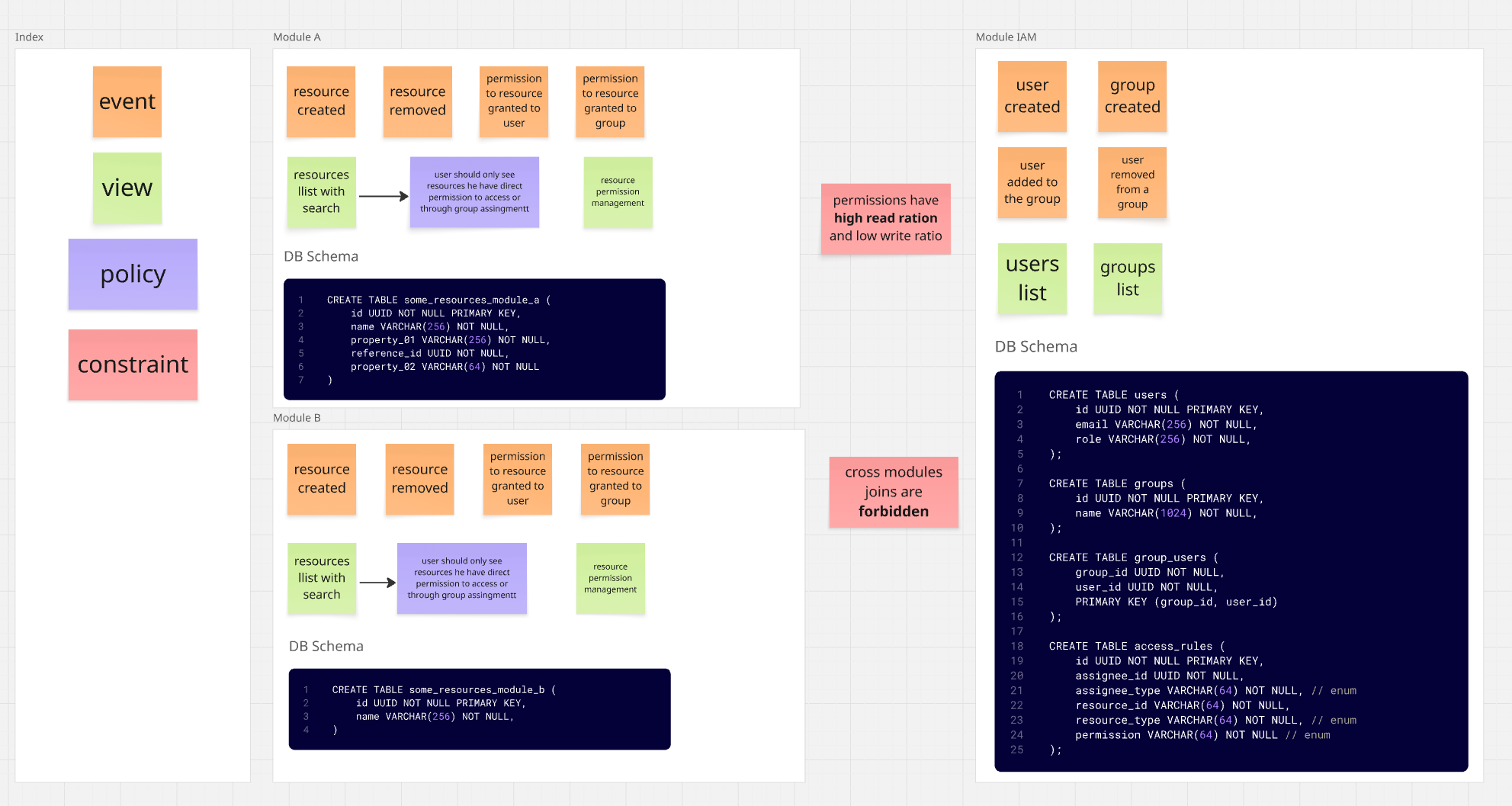
Le système de permissions ici est un peu complexe. Il est principalement basé sur ACL (Access Control List),
ce qui signifie accorder des permissions aux ressources directement aux utilisateurs ou aux groupes.
En plus de cela, il y a aussi du RBAC (Role Based Access Control), où les utilisateurs avec des
rôles spécifiques ont des permissions définies pour des parties spécifiques du système.
Nous avons aussi partiellement ABAC (Attribute Based Access Control), où les permissions sont dérivées des attributs de l'utilisateur,
dans ce cas, l'appartenance au groupe.
Ça vous dit quelque chose ? Ce n'est pas un cas si unique que vous pourriez le penser. Mais bon, venons-en au fait.
Le Problème
Comme vous pouvez le voir dans le diagramme, le système de permissions est défini dans le module IAM - c'est là que nous stockons
les informations sur :
- Les utilisateurs et leurs rôles
- Les groupes auxquels les utilisateurs appartiennent
- Les permissions pour des ressources spécifiques
Les modules A et B, quant à eux, sont responsables de la gestion de leurs propres ressources mais doivent vérifier qu'un utilisateur donné a accès à une ressource spécifique.
Le schéma de dépendance des modules ressemble donc à ceci : Les modules A et B connaissent l'existence du module IAM (ils en dépendent), mais le module IAM lui-même n'a aucune idée que les modules A et B existent.
Le problème auquel l'équipe a été confrontée était le suivant : "Comment créer une liste paginée de ressources dans un module donné basée sur les permissions utilisateur ?"
De plus, la liste de ressources doit permettre :
- Le filtrage basé sur les caractéristiques de la ressource
- Le tri basé sur les caractéristiques de la ressource
- Le retour d'une seule page sélectionnée
Ces exigences rendent l'implémentation beaucoup plus difficile. Si nous n'avions pas de filtrage/pagination, nous pourrions simplement
interroger directement le module IAM avec une demande de retour des ressources pour un utilisateur donné.
Les caractéristiques de ressource sont tous leurs paramètres et attributs qui ont un sens et une signification principalement dans leur
propre contexte. Des exemples de caractéristiques de ressource pourraient être son nom ou sa date de création. Ce sont des paramètres sur lesquels
l'utilisateur devrait pouvoir trier ou filtrer, mais qui n'existent pas dans le module IAM.
Mais sans caractéristiques de ressource sur lesquelles nous pouvons filtrer/trier, le module IAM peut au mieux retourner toutes les ressources,
et nous devrions faire le filtrage du côté du module. Ce n'est pas exactement une solution scalable.
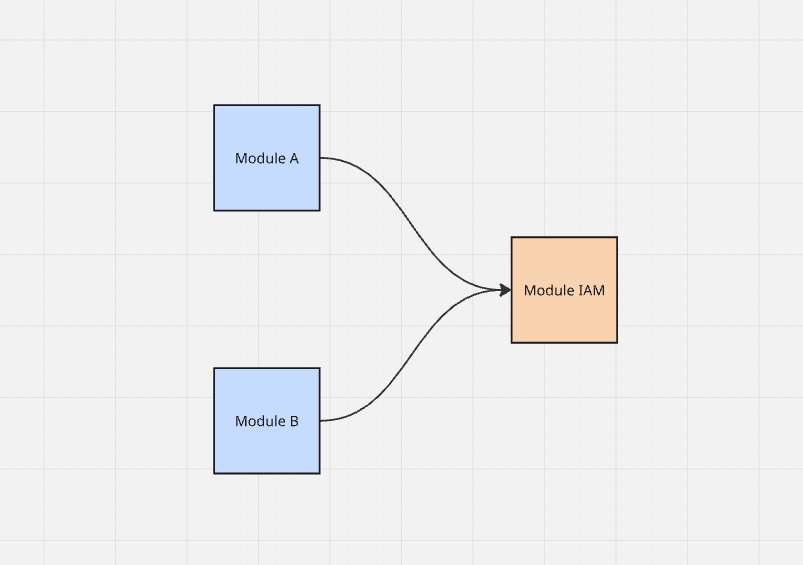
Ne sachant pas comment sortir de cette situation, l'équipe a décidé (consciemment ou non) de briser les règles de modularisation et de coupler les modules au niveau de la base de données.
Puisque le système est déployé en tant que monolithe modulaire et que chaque module a accès à la même base de données (chaque module a ses propres tables avec un préfixe approprié),
théoriquement rien n'empêche de construire une requête SQL qui retourne une liste de ressources pour un module spécifique
et de la joindre aux tables de permissions du module IAM pour filtrer les ressources auxquelles l'utilisateur n'a pas accès.
Rapide, simple et ça fonctionne même.
Cela pourrait probablement coexister paisiblement, sauf qu'il y a une nouvelle exigence : nous devons extraire l'un des modules du monolithe...
Et c'est là que ça se complique. Comment extraire le Module A en tant que service indépendant quand il est étroitement couplé au niveau de la
base de données avec le module IAM ? Si nous supprimons le join vers les tables IAM, le contrôle d'accès
cessera de fonctionner.
Ci-dessous, je présenterai des techniques qui nous permettront d'extraire ce module du monolithe sans perdre de fonctionnalité, briser les règles de modularisation ou changer les dépendances entre modules.
Lors de la conception d'un monolithe modulaire, il vaut la peine d'essayer une approche légèrement différente. Au lieu de préfixer les tables, vous pouvez créer des bases de données/schémas séparés pour chaque module au sein d'un seul serveur de base de données, ce qui rend beaucoup plus difficile la création d'un couplage accidentel au niveau des requêtes SQL.
Séparation des Responsabilités
Et si ce n'était pas le module IAM qui était responsable des permissions accordées aux ressources
qui n'existent que dans un module spécifique ?
Une approche possible (probablement la meilleure pour beaucoup) est la séparation des responsabilités, ce qui signifie que IAM
gère l'autorisation, les utilisateurs, leurs rôles et les groupes auxquels ils sont assignés.
Les modules eux-mêmes gèrent les règles de permissions pour les ressources. En pratique, cela signifie déplacer les tables access_rules
vers le Module A et le Module B.
Le résultat serait une architecture similaire à celle ci-dessous :
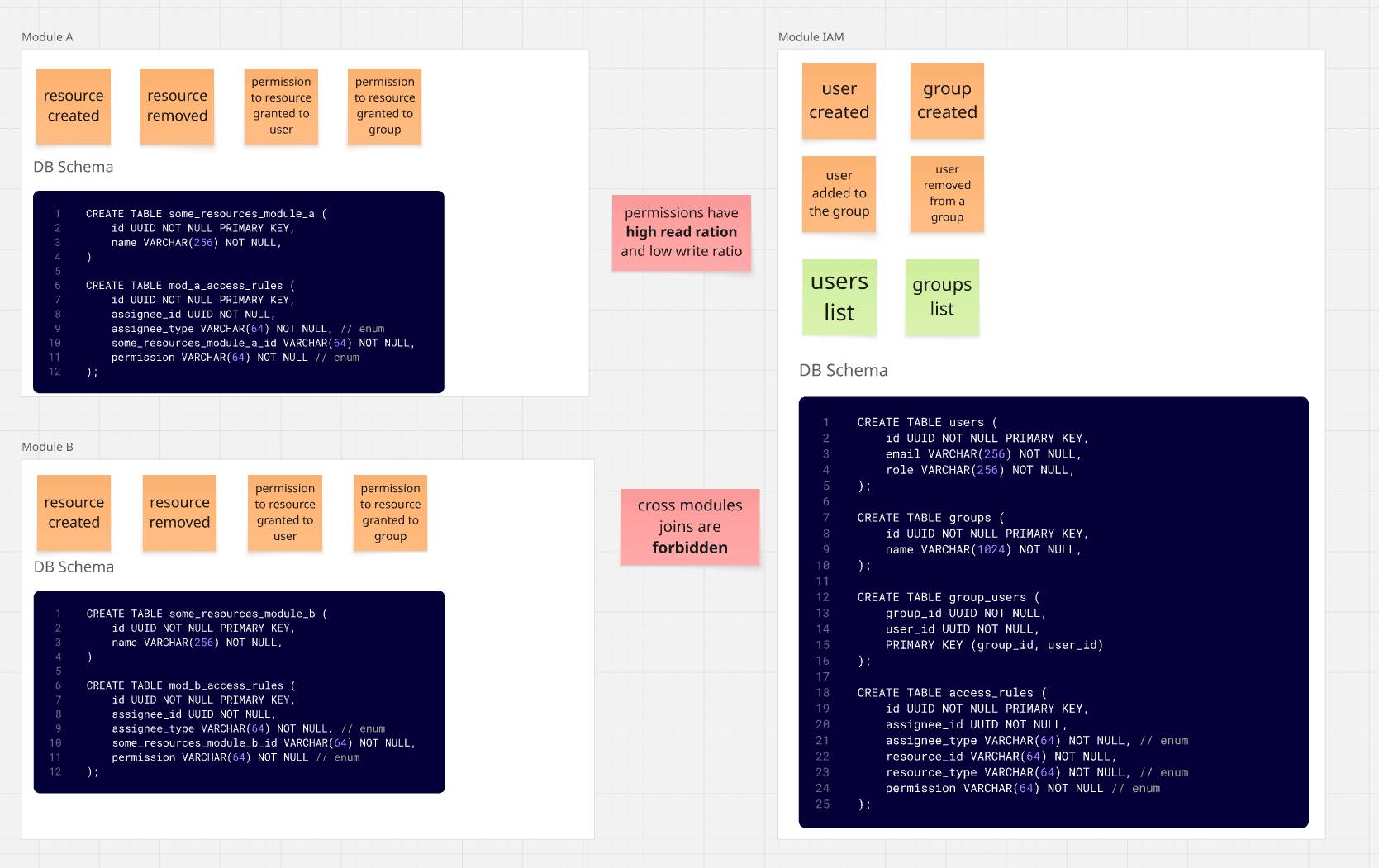
Aucun des modules n'a besoin de faire des allers-retours vers IAM pour obtenir une liste de ressources disponibles
pour un utilisateur sélectionné.
Nous avons bien une certaine duplication - nous devons essentiellement répéter la logique de permissions pour chaque module existant et l'intégrer dans les mécanismes de module existants.
Note : Ici, vous pourriez être tenté de créer un composant. À moins que vous n'ayez des personnes dans vos équipes expérimentées dans la construction de bibliothèques/composants, il est préférable de commencer par la duplication. À long terme, la duplication fait beaucoup moins mal que la mauvaise abstraction.
Mais est-ce suffisant ?
Pas tout à fait. Si nous regardons la table de permissions, nous remarquerons que les permissions peuvent être accordées directement à un utilisateur ou à un groupe auquel l'utilisateur appartient.
Cela signifie que dans le Module A, nous accordons des permissions à une ressource pour le groupe Groupe 01, qui inclut
l'Utilisateur 01 et l'Utilisateur 02.
Grâce à cela, les deux utilisateurs ont accès à la ressource.
Mais que se passe-t-il si nous supprimons un utilisateur du groupe sélectionné ?
Nous pouvons aborder cela de deux façons :
- Lors de chaque vérification d'accès, nous interrogeons le module
IAMpour la liste des groupes de l'utilisateur - Nous acceptons la
cohérence éventuelleet conservons les groupes d'utilisateurs dans la session, en la rafraîchissant toutes les quelques/dizaines de minutes
La première solution est la plus simple à implémenter, ne viole pas les limites de responsabilité des modules, mais pourrait rapidement devenir un goulot d'étranglement.
Bien sûr, cela n'arrivera pas immédiatement. De plus, en raison de la nature des données (plus de lectures que d'écritures), nous pouvons aussi décharger la base de données grâce à des mécanismes de mise en cache appropriés.
Pour la solution numéro deux, nous devons nous assurer que c'est même une solution acceptable du point de vue métier.
Projection
Une autre approche pour résoudre le problème consiste à conserver la structure de permissions dans le module IAM, mais
à introduire des mécanismes permettant au Module A et au Module B de synchroniser
la table de permissions avec une projection locale.
Cette projection n'est rien d'autre qu'une forme simplifiée de la table access_rules répliquée dans un module spécifique.
En conséquence, nous obtenons encore une certaine duplication, mais le Module A et le Module B
ne se concentrent pas sur la gestion des permissions - cette responsabilité est toujours déléguée au module IAM.
Leur responsabilité se réduit à synchroniser les permissions avec le module de permissions.
Mais comment et quand effectuons-nous cette synchronisation ? À chaque fois que nous accordons des permissions à une ressource.
Le Module A, lors de l'octroi de permissions à un utilisateur ou à un groupe pour une ressource, communique d'abord
avec le module IAM.
Nous faisons de même lors de la révocation de l'accès à une ressource. D'abord, nous supprimons l'entrée dans le module IAM, puis
nous supprimons l'entrée dans la projection locale.
Mais que se passe-t-il si nous supprimons un utilisateur d'un groupe sélectionné ?
Nous revenons ici essentiellement au même problème que nous avions dans l'approche précédente. Nous pouvons soit
récupérer la liste des groupes de l'utilisateur du module IAM à chaque fois, soit accepter la cohérence éventuelle.
La différence entre séparation et projection est très petite. Mais avec les projections, nous pouvons aller plus loin.
Événements
Le module IAM peut également propager des événements liés à :
- L'ajout d'un utilisateur aux groupes
- La suppression d'un utilisateur d'un groupe
- La suppression d'un groupe
Pour maintenir la structure de dépendance appropriée, ces événements ne peuvent pas être publiés "vers un destinataire spécifique".
Nous devons appliquer une approche Pub/Sub ici, où IAM publie des événements vers un
Topic spécifique, auquel les modules intéressés peuvent s'abonner.
Grâce à cela, les deux modules recevront une copie du même événement, qu'ils pourront gérer indépendamment.
Lors de la construction d'une projection, nous pouvons aussi simplifier considérablement sa structure en décomposant les groupes en listes d'utilisateurs.
Si un groupe reçoit une permission d'accès à une ressource, au lieu de stocker
une entrée dans la projection représentant le groupe, nous pouvons créer une entrée pour chaque utilisateur du groupe.
Grâce à cela, lors de la vérification d'accès, nous n'avons pas du tout besoin de demander au module IAM. Nous avons juste besoin de
répondre de manière appropriée aux événements propagés par le module IAM :
- Ajout d'un utilisateur à un groupe
- Suppression d'un utilisateur d'un groupe
- Suppression d'un groupe
Essentiellement, seuls ces événements nous importent. L'ajout d'un groupe ou d'un utilisateur n'affecte vraiment rien, nous pouvons donc les ignorer/filtrer en toute sécurité.
Fiabilité des Événements
Bien sûr, une approche basée sur les événements comporte certains risques. L'un d'eux est, par exemple, l'ordre des événements perturbé.
Par exemple, nous recevons d'abord un événement "utilisateur supprimé du groupe", et seulement après l'événement "utilisateur ajouté", alors qu'en
réalité ces événements se sont produits dans l'ordre inverse.
Oui, cela peut être un problème, surtout lorsque le message contenant l'événement inclut également tous les détails de cet événement.
Mais nous pouvons y remédier en décidant d'utiliser des événements anémiques - c'est-à-dire des événements qui essentiellement ne contiennent que les identifiants des ressources qu'ils concernent, et pour tout le reste, vous devez aller au module source.
Comparons les deux approches en utilisant l'événement UserRemovedFromGroup comme exemple :
Événement Riche (Rich Event)
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"userName": "jan.kowalski",
"userEmail": "[email protected]",
"groupId": 456,
"groupName": "Administrators",
"groupPermissions": ["read", "write", "delete"],
"removedBy": {
"userId": 789,
"userName": "admin"
}
}
}
Événement Anémique (Anemic Event)
{
"eventId": "550e8400-e29b-41d4-a716-446655440000",
"eventType": "UserRemovedFromGroup",
"occurredAt": "2025-10-18T10:30:00Z",
"payload": {
"userId": 123,
"groupId": 456
}
}
La différence est fondamentale. Avec un événement riche, toutes les informations sur l'utilisateur, le groupe et les permissions sont contenues dans l'événement. Si l'ordre des événements est perturbé, notre projection peut se retrouver dans un état incohérent.
Un événement anémique, en revanche, ne contient que des identifiants. Après avoir reçu un tel événement, le consommateur doit
faire une requête supplémentaire au module IAM pour obtenir l'état actuel. Grâce à cela, quel que soit l'ordre
de réception des événements, nous obtiendrons toujours la version la plus à jour des données.
Scénario Problématique pour les Événements Riches
Imaginons la séquence d'événements suivante dans le module IAM :
10:00:00- Utilisateur ajouté au groupe "Administrators"10:00:05- Utilisateur supprimé du groupe "Administrators"
Le consommateur dans le Module A reçoit les événements dans l'ordre inverse :
- Reçoit
UserRemovedFromGroup(avec les données de 10:00:05) - Reçoit
UserAddedToGroup(avec les données de 10:00:00)
Avec les événements riches, la projection dans le Module A montre que l'utilisateur appartient au groupe (car le dernier événement reçu était "ajout"), même si en réalité il en a déjà été supprimé.
Avec les événements anémiques, quel que soit l'ordre de réception, le Module A exécutera une requête vers IAM et obtiendra l'état actuel - l'utilisateur n'appartient pas au groupe.
Les événements anémiques réduisent le risque d'incohérence, mais ne l'éliminent pas complètement. Il existe toujours la possibilité qu'entre la réception de l'événement et la requête à IAM, l'état change. Vous pourriez donc envisager d'ajouter un numéro de version ou un horodatage aux événements et de les vérifier lors de la mise à jour de la projection. Bien que les mécanismes de protection dépendront largement du trafic et de la fréquence des changements.
Voici à quoi cela ressemble :
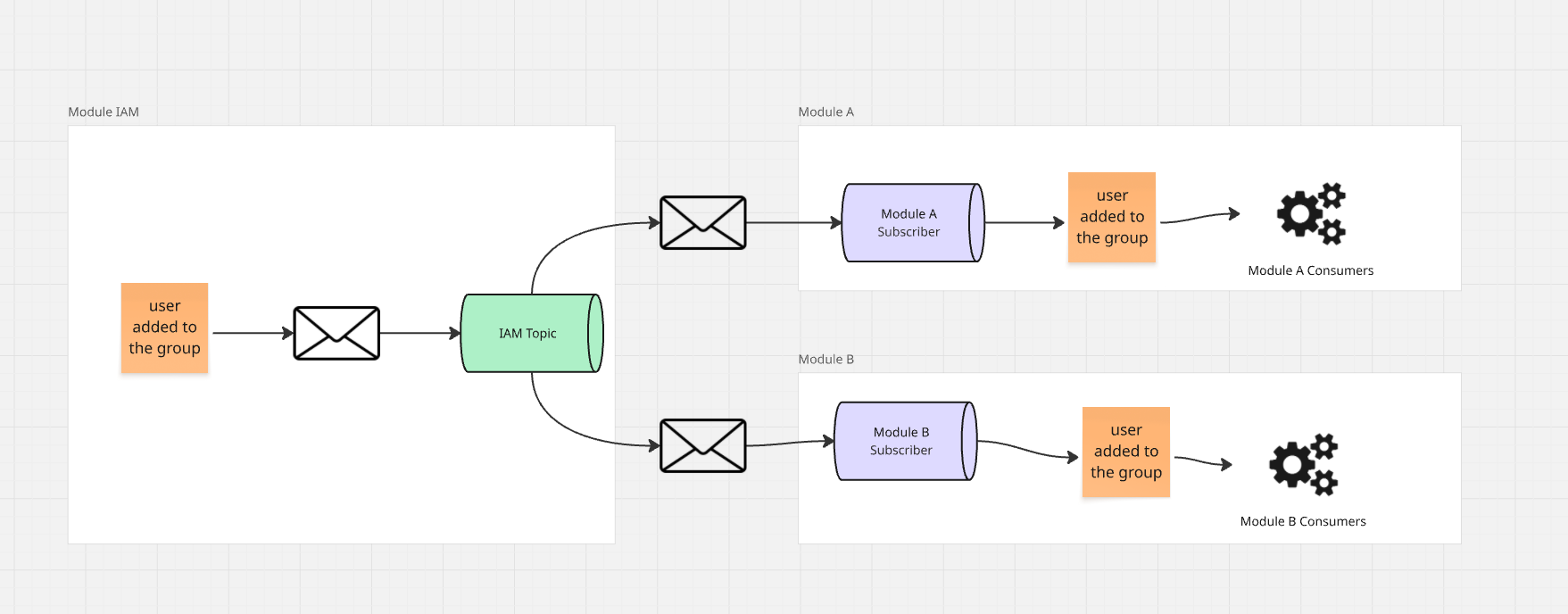
Lorsque le consommateur du Module A reçoit des informations, son travail est d'aller au module IAM et de lui demander
toutes les règles pour un groupe spécifique. Le module IAM peut retourner les enregistrements de la table de permissions concernant
un groupe spécifique, et ensuite, si des règles existent, nous pouvons demander les utilisateurs de ce groupe et dans
la projection locale du module construire une projection de permissions pour eux.
Nous pouvons aussi nous faciliter un peu la vie et ajouter au protocole de communication avec le module IAM la capacité
de récupérer une structure plate de permissions, qui retourne non pas le groupe mais une liste d'utilisateurs du groupe avec des permissions pour
une ressource spécifique.
Note : Pour fournir des garanties supplémentaires de livraison d'événements, envisagez d'implémenter le modèle Outbox.
Attendez, mais le module IAM ne deviendra-t-il pas à nouveau un goulot d'étranglement ?
Pas exactement. Ce qui importe ici n'est pas seulement la requête elle-même, mais plutôt sa fréquence. Le contrôle des permissions est l'un de ces processus où nous demandons des permissions beaucoup plus souvent que nous ne les modifions.
Bien sûr, ne me croyez pas sur parole - si vous avez un système existant avec contrôle de permissions, il vaut la peine de simplement le mesurer.
Mais pour en revenir au point, lors de l'utilisation d'événements anémiques, nous n'avons pas à nous soucier autant de l'ordre dans lequel ils sont reçus. Nous ne nous appuyons pas sur le contenu de l'événement mais seulement sur l'identifiant de ressource qu'il concerne, ce qui rend la construction de projections beaucoup plus facile.
Mais cela a un coût - maintenant après chaque événement, nous devons aller à la source pour déterminer l'état réel.
Il vaut donc la peine d'analyser cette approche du point de vue des performances.
Il existe cependant plus de techniques pour gérer les événements. Vous pouvez en trouver une sur https://event-driven.io/.
Duplication
Dans les deux approches, cependant, le problème de la duplication se pose. Bien que dans ce cas, "problème" soit probablement le mauvais mot. C'est simplement un coût de la modularisation dont on ne parle tout simplement pas.
Que nous décidions de la séparation des responsabilités ou de la construction de projections, les Modules A et B dupliqueront la logique liée aux permissions dans une plus ou moins grande mesure.
Donc, quel que soit notre modèle de déploiement (monolithe / microservices) et quelle que soit la façon dont nous séparons les limites de modules et leurs responsabilités, nous devons simplement nous préparer à ce coût.
Mon conseil ici est toujours de commencer par la duplication. Même si nos implémentations ne diffèrent pas du tout entre les modules.
Il est beaucoup plus facile d'extraire des parties communes de solutions existantes que de concevoir des parties communes pour des solutions qui n'existent pas encore.
Qu'est-ce qui est Mieux ?
Il n'y a pas de réponse claire à cette question. Mais nous pouvons essayer d'analyser notre situation et de choisir une solution qui nous permettra d'extraire l'un des modules et de nous débarrasser du couplage au niveau de la base de données.
Pour le module qui doit être extrait, je suggérerais (si possible) la séparation des responsabilités et le déplacement de la gestion des permissions de ressources vers ce module.
Puisque nous devons de toute façon faire du travail, puisque nous devons de toute façon séparer physiquement ce module de notre monolithe,
nous pourrions aussi bien aller plus loin et réduire sa dépendance à
IAM encore plus à un coût relativement faible.
Mais une telle opération a-t-elle du sens pour les modules existants ?
Pour les modules qui n'ont pas besoin d'être extraits et continueront à vivre dans le monolithe modulaire, je suggérerais une approche basée sur la projection, mais pas nécessairement avec des événements.
Projections Sans Événements
C'est une technique qui ne fonctionnera pas dans une approche microservices, mais peut aider comme solution provisoire. Non seulement aider, mais aussi indiquer la voie à suivre. Vous pouvez l'implémenter à faible coût, en obtenant essentiellement la même chose qu'avec une approche basée sur les événements.
Regardons cela sous un angle différent. Pub/Sub est essentiellement un mécanisme qui nous permet une certaine forme de réplication. Grâce aux événements, nous savons que quelque chose s'est passé à un moment donné dans un module donné.
Et si au lieu de publier un événement vers un Topic, nous utilisions des Vues Matérialisées ?
Oui, je sais - beaucoup de gens voient probablement des drapeaux rouges maintenant. Je veux dire, des vues matérialisées ? De la logique côté base de données au lieu du code ?
Eh bien, ce n'est pas une solution idéale. Certes, nous nous débarrassons du couplage au niveau SQL, mais en échange nous obtenons un couplage différent - cette fois au niveau de la base de données.
Mais si nous abordons cela de manière pragmatique, nous échangeons essentiellement juste le mécanisme de transport. Au lieu de construire du pub/sub, d'implémenter le modèle Outbox, de gérer les erreurs de communication réseau, les tentatives, etc., nous pouvons simplement laisser la base de données gérer la réplication des données.
Si pour une raison quelconque cela cesse de nous convenir - comme lorsque le rafraîchissement de la vue matérialisée devient trop coûteux et commence à charger inutilement notre base de données - rien ne nous empêchera de passer aux projections.
Mais avant d'en arriver là, nous pouvons aussi essayer de mettre le processus de rafraîchissement lui-même dans une file d'attente dans le module IAM
et de l'exécuter de manière asynchrone. Nous obtiendrons un léger retard, bien que dans ce cas, il devrait être à un niveau acceptable.
L'essentiel est de comprendre qu'une Vue Matérialisée n'est ni une mauvaise ni une bonne solution - elle nous donne juste
la capacité d'introduire une séparation simplifiée relativement rapidement sans avoir à construire tout le mécanisme basé sur les événements.
Mais lorsque la séparation complète/performance/verrouillage du fournisseur ou quoi que ce soit d'autre commence à nous gêner ici, il ne devrait pas y avoir de problèmes majeurs pour passer aux projections.
C'est exactement ce qui fait de Vue Matérialisée une solution intéressante.
La Solution Idéale
N'existe pas...
Et c'est probablement la chose la plus importante que je veux transmettre dans cet article.
Même si nous parvenons à réduire le problème uniquement à la technologie, et même si par miracle nous sommes tous d'accord que le problème A doit être résolu avec le modèle/technique/architecture B...
Rien de tout cela ne pourrait avoir d'importance car l'entreprise pourrait simplement ne pas approuver une refonte majeure...
Et ce n'est pas forcément de la mauvaise foi ou de l'ignorance - parfois nous n'avons tout simplement pas les ressources.
Il est difficile de justifier pourquoi nous devrions passer du temps à déplacer la gestion des permissions vers les modules quand tout fonctionne et génère des profits.
Tout aussi difficile qu'il sera d'argumenter pourquoi soudainement, avec une exigence d'extraire un module, nous devons corriger tous les autres, en ajoutant de la communication asynchrone, des événements, des mécanismes de nouvelle tentative, de récupération, etc.
Il vaut la peine d'accepter que le monde n'est pas parfait, n'est pas noir et blanc, et nous devrons souvent choisir entre plusieurs solutions imparfaites.
Ce qui peut sembler absolument incorrect dans un endroit pourrait être acceptable dans un autre contexte, ou même souhaitable.
Aide
Si vous rencontrez des problèmes similaires dans votre projet et que vous n'êtes pas tout à fait sûr de la façon de les résoudre,
contactez-moi, et ensemble nous trouverons une solution parfaitement adaptée à vos besoins.
Je vous encourage également à visiter Discord - Flow PHP, où nous pouvons parler directement.
